2. ターミナル環境#
多くの読者は、これまでWindowsやmacOSなどにおけるデスクトップ環境でコンピュータを使用してきたと思う。このような計算機のインタフェースのことを特に グラフィカル・ユーザ・インタフェース (GUI) と呼ぶ。
一方で、プログラミングを行う場合には、ターミナルと呼ばれる環境において、テキストとしてのコマンドを入力しながら計算機を操作することが一般的である。このようなコマンドに基づく計算機のインタフェースのことを コマンドライン・インタフェース (CLI) と呼ぶ。
本節では、UNIX系のオペーレーティング・システム (OS)におけるターミナル環境の基本的な使い方について学ぶ。
UNIX
UNIXとは、1969年にAT&TのBell研究所で開発されたオペレーティング・システム (OS)の一つで、UNIXの後継にあたるLinuxやmacOSなどのOSはUNIX系OSとも呼ばれる。ちなみに、WindowsはUNIXベースではなく、Microsoftが独自に開発したOSであるため仕様が少々異なる。
2.1. 準備#
本節では、ターミナル環境を用いた演習のために GitHub Codespaces を利用する。以下のGitHubリポジトリに演習用のデータが用意されているので、GitHubアカウントを作成した上で、リポジトリのページにアクセスする。
tatsy-classes/terminal-practice
画面の右側にある Fork ボタンをクリックして、リポジトリを自分のアカウントにコピーしよう。
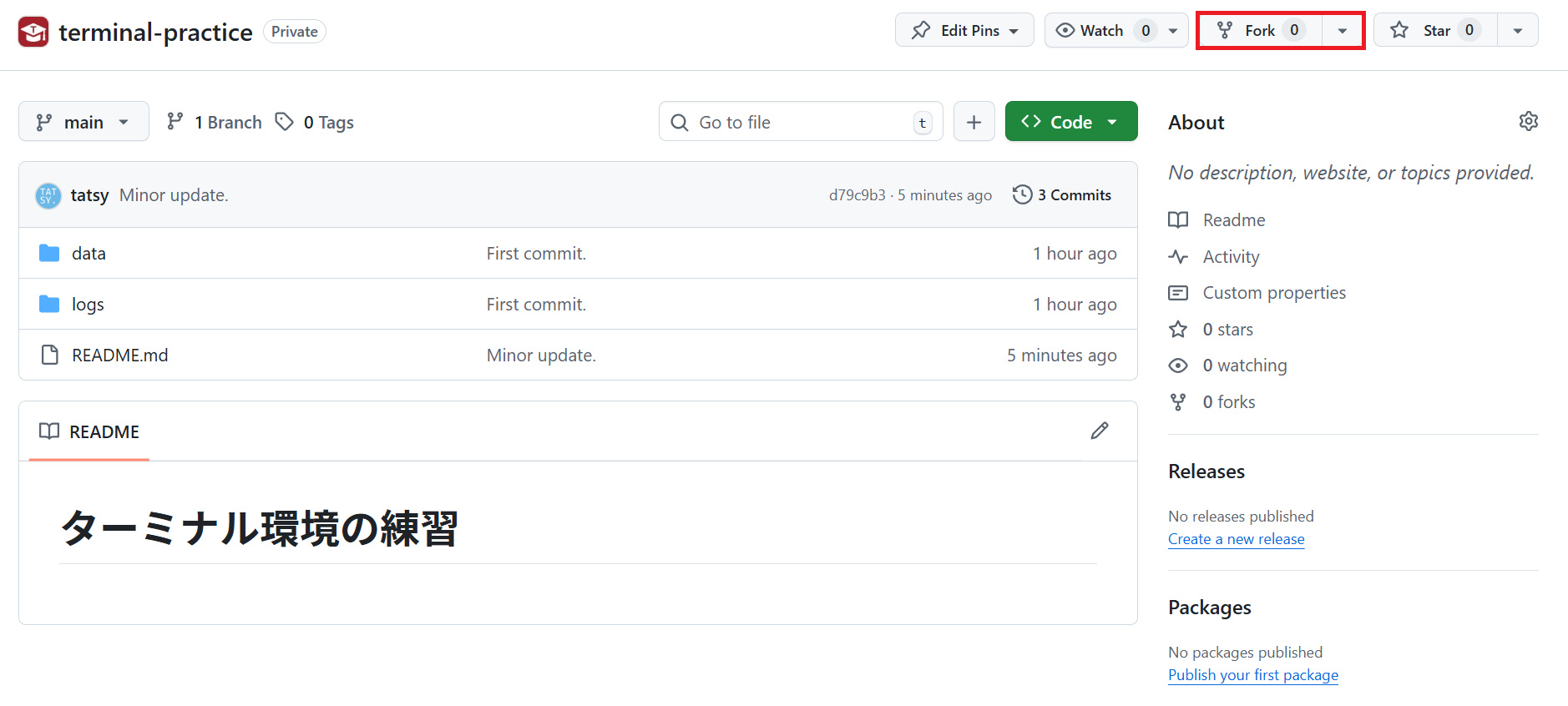
各自のGitHubアカウントにリポジトリがコピーされたら、次に Code ボタンをクリックして表示されるメニューから「Create a codespace on main」を選択する。
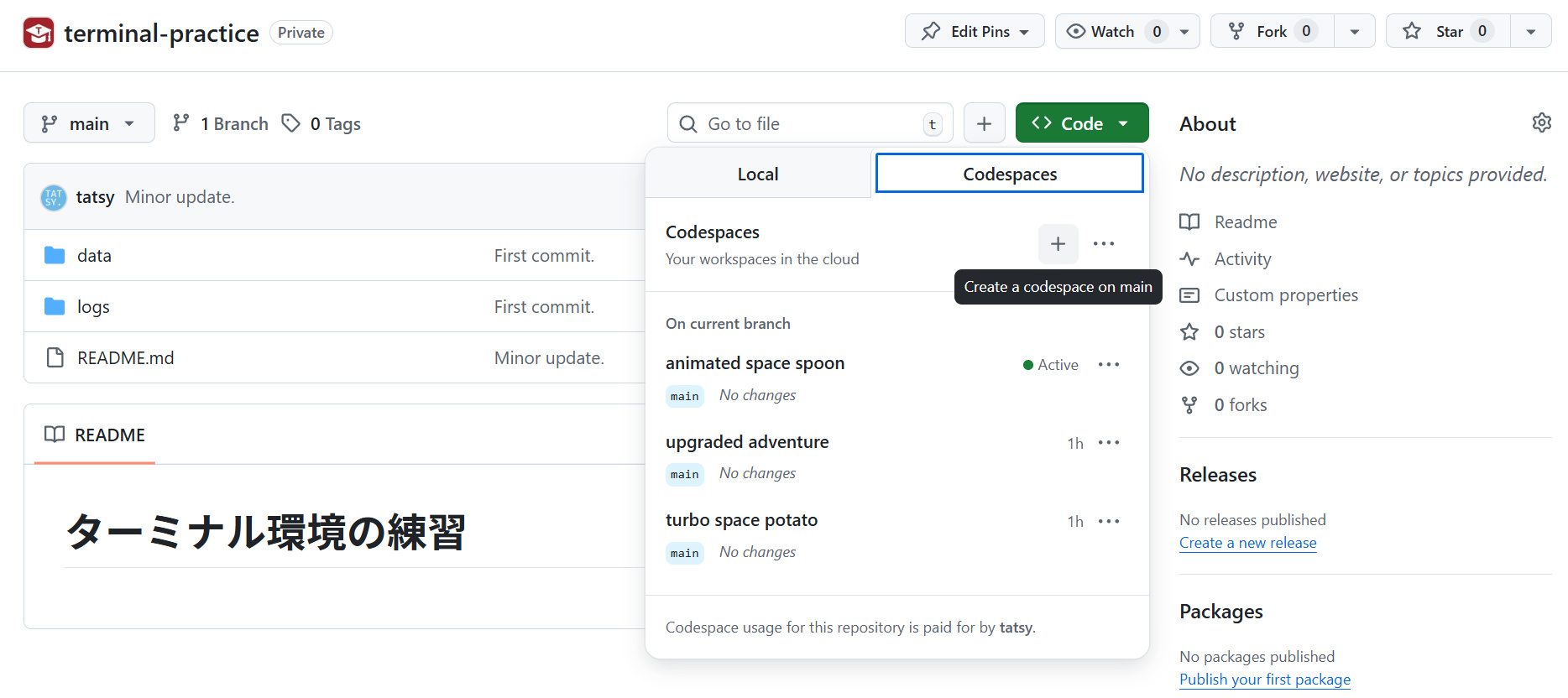
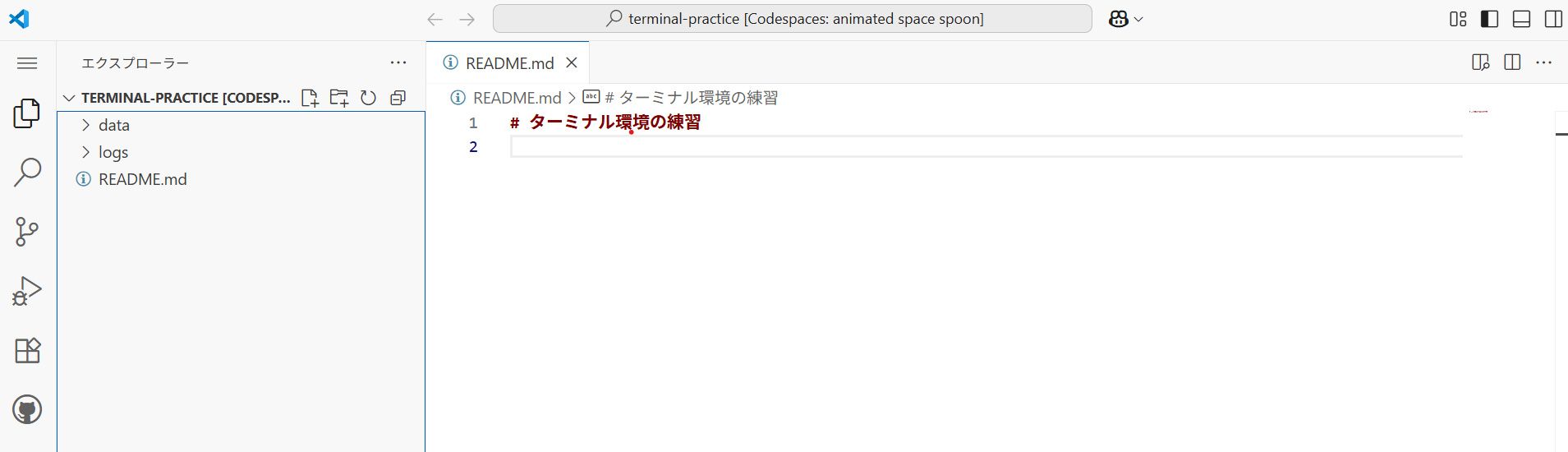
すると、以下のようなCodespaceの環境 (Web版のVisual Studio Code) が起動する。
なお、Codespaceは作成ごとに適当な名前がつけられるので、次に開く際には前述の Code ボタンを押したあとで「On current branch」の下に現れるCodespaceの一覧から選択すれば良い。
Codespaceが開いたら、画面左上のメニューから、「ターミナル」→「新しいターミナル」を選択すると、画面の下側にターミナルのウィンドウが表示される。
ターミナルとシェル
ターミナルと混同されやすい用語に シェル がある。ターミナルとは、ユーザが計算機を操作するためのインタフェースを指すのに対して、シェルとは、ターミナル上で動作し、ユーザが入力したコマンドを実行するプログラムを指す。代表的なシェルにはbashやzshなどの他、Windows上で主に用いられるPowerShellなどがある。
2.2. 基本的なコマンド#
ターミナル上でシェルを通して行える操作は非常に幅広く、デスクトップ環境で行える操作の多くはターミナル環境でも実行できるほか、システム管理向けの高度な操作やプログラミングに必要なコンパイル等の処理も可能である。
ターミナル上では $ や > などの記号が行の先頭に表示されていることが多く、これはユーザからのコマンド入力を待っている状態である。これらの記号は プロンプト記号 などと呼ばれる。本資料では、プロンプト記号として $ を用いることにする。
ターミナル上でコマンドを実行するには、プロンプト記号の後にコマンドと、そのオプションや引数を入力してEnterキーを押せば良い。
$ echo Hello
Hello
上記の例では、echo がコマンドであり、 Hello がコマンド引数である。echo はコマンド引数として与えられた文字列をそのまま出力する基本的なコマンドである。
コマンドのオプションは -a や --all のようにハイフンから始まる。ハイフン1つから始まるオプションは通常、--all などのハイフン2つから始まるオプションの省略形で、一つのハイフンの後に続くアルファベットは多くの場合1文字である (例外もある)。
$ grep -h # grep --help と同じ意味
ただし、一部のコマンドは、1文字のオプションを1つのハイフンの後にまとめて書く形式をサポートしている。
$ ls -la # ls -l -a と同じ意味
ターミナルを使いこなすコツ
ターミナルを使いこなすコツは なるべくタイプの回数を減らす ということである。シェルにはコマンドやファイルパスの 補完機能 が備わっているので、それをできる限り活用しよう。
通常、補完はTabキーを押すことで行われるので、「少しタイプ」→「Tabキーを押す」→「Enterを押す」のような流れで、かなり早くターミナルを操作できるようになる。
シェルの便利な操作法
ターミナル上ではマウスが使えないので、コマンドを打ち間違えたときなどはマウスでクリックする代わりに矢印キーなどでカーソル位置を戻して修正しなければならない。
このような場合に覚えておくと便利なショートカットを以下に示す (シェルによって動作が異なる場合もある)。
Ctrl + A: 行の先頭に移動Ctrl + E: 行の末尾に移動Ctrl + W: カーソル位置から前の単語までを削除Ctrl + K: カーソル位置から行末までを削除Ctrl + Y: 直前に削除したテキストを貼り付け
この他にも多くのショートカットが存在するので、興味があれば調べてみてほしい。
ファイルシステムの操作#
デスクトップ環境においては、WindowsのエクスプローラやmacOSのFinderのようなファイルマネージャを用いて、視覚的にディレクトリの移動やディレクトリ内のファイル閲覧ができるが、ターミナル環境では、コマンドを用いてこれらの操作を行う。
ターミナル環境を使用する上で、最も重要なことは、 自分が今どのディレクトリの中にいるのかを把握すること である。
Codespace上でターミナルを開くと、
@username -> /workspaces/terminal-practice (main) $
のような文字が表示される。この中で /workspaces/terminal-practice の部分が、現在のディレクトリを表している。このように、現在、ターミナルで開いているディレクトリのことを特に カレントディレクトリ (current directory) と呼ぶ。
pwdコマンド#
カレントディレクトリをコマンドを用いて調べる場合には pwd (print working directory) コマンドを使用する。
$ pwd
/workspaces/terminal-practice
このように pwd コマンドを実行すると、カレントディレクトリの場所がコンピュータ内での絶対位置を表す 絶対パス で表示される。
絶対パスと相対パス
ターミナルにおけるファイルやディレクトリのパスには、絶対パス と 相対パス の2種類がある。
絶対パス: ルートディレクトリからの完全なパスを示す。例えば、
/workspaces/terminal-practice/data/fruits.txtのように、最初の/から始まるパスが絶対パスである。相対パス: カレントディレクトリを基準にしたパスを示す。例えば、カレントディレクトリが
/workspaces/terminal-practiceの場合、data/fruits.txtのように書くことができる。
lsコマンド#
カレントディレクトリ内に存在するファイルやディレクトリの一覧を表示するには ls (list) コマンドを使用する。
$ ls
README.md data fizzbuzz.py images log.txt logs
また、ls コマンドは、引数にディレクトリを取ることができ、例えば data というディレクトリの中身を確認したければ、以下のように入力する。
$ ls data
fruits.txt numbers.txt romeo_and_juliet.txt
このように、data ディレクトリの中には fruits.txt と numbers.txt という2つのファイルが存在することが分かる (Codespaceの画面で確認できるものと同じになっている)。
cdコマンド#
カレントディレクトリから別のディレクトリに移動するには cd (change directory) コマンドを使用する。例えば、data という名前のディレクトリに移動する場合には、以下のように入力する。
$ cd data
このコマンドを実行したあとに pwd コマンドを実行すると、以下のように表示される。
$ pwd
/workspaces/terminal-practice/data
反対に、dataから元いた1つ上のディレクトリ (ペアレントディレクトリ (parent directory) と呼ぶ)に戻るには
$ cd ..
のように1つ上の階層を表す .. を引数に指定する。
また、UNIX系のOSには、各ユーザの占有ディレクトリである ホームディレクトリ (home directory) という概念があり、cd コマンドに引数を指定せずに実行すると、ホームディレクトリに移動する。
$ cd # ホームディレクトリに移動
$ pwd # ホームディレクトリを確認
/home/codespace
補足: ファイルの属性#
前述のls コマンドには、いくつかのオプションが用意されており、よく用いられるものは -a (all) オプションと -l (long) オプションがある。
-a オプションは、通常の ls コマンドでは表示されない隠しファイルを表示するためのオプションである。UNIX系のOSでは、隠しファイルはドット (.) から始まるファイル名・フォルダ名を持つ。
実際に ls -a コマンドを実行すると、以下のように表示される。
$ ls -a
. .. .git .gitignore README.md data fizzbuzz.py images log.txt logs
表示されたフォルダの中で . はカレントディレクトリを表し、.. は一つ上の階層のディレクトリを表す。
-l オプションは、ファイルの所有者やパーミッション、ファイルサイズ、更新日時といった詳細な情報をファイル名とともに表示するためのもので、次のような出力が得られる。
$ ls -l
total 24
-rw-rw-rw- 1 codespace root 33 Sep 11 07:56 README.md
drwxrwxrwx+ 2 codespace root 4096 Sep 16 04:03 data
-rw-rw-rw- 1 codespace codespace 391 Sep 16 05:55 fizzbuzz.py
drwxrwxrwx+ 2 codespace codespace 4096 Sep 18 09:52 images
-rw-rw-rw- 1 codespace codespace 22 Sep 17 05:27 log.txt
drwxrwxrwx+ 2 codespace root 4096 Sep 11 07:55 logs
この表示内容の中で、特に重要なのは、最初の列に表示されている パーミッション (permission) の情報である (例えば -rw-rw-rw)。パーミッション情報は、合計10文字で表されている。
先頭の文字は -, d, l のいずれかで、ファイル (フォルダ)の種類を表す。- は通常のファイル、d はディレクトリ、l はシンボリックリンクを表している。なお、シンボリックリンクとは、あるファイルやディレクトリをコピーする代わりに、その場所への参照を作成する機能で、Windowsのショートカットに似た機能である。
その後に続く9文字は、ファイルやディレクトリに対するアクセス権限を表しており、r、w、xの3つの文字の組み合わせで表されている。
このうち、r は読み取り、 w は書き込み、x は実行の権限を表している。パーミッション情報は rwxrwxrwxのように3文字ずつ3つのグループに分けられており、最初の三文字はファイルの所有者に対する権限、次の三文字はファイルの所有グループに対する権限、最後の三文字は全てのユーザに対する権限を表している。
多くの場合、ファイルのパーミッションは rw-r--r-- 、すなわち、所有者は読み取りと書き込みが可能で、その他のユーザは読み取りのみが可能な設定になっている。また、フォルダのパーミッションは rwxr-xr-x のように、所有者は読み取り、書き込み、実行全てが可能で、その他のユーザは読み取りと実行が可能な設定になっていることが多い。
また、パーミッションは、3桁ずつのグループを2進数の数字とみなして3桁の数字で表すことも多い。例えば rw-r--r-- は二進数で 110/100/100から644 と表され、rwxr-xr-x は 111/101/101 から 755 と表される。
ファイルサイズとブロック数
ls -l コマンドの出力における2行目の total 24 は、カレントディレクトリ内のファイルとフォルダが使用しているディスクブロックの合計数を表している。
1ブロックの大きさはシステムによって異なるが、上記の例では1ブロックが1024バイト (1KB)となっている。ブロック数を数える場合、ファイルの実際のサイズが特定のブロック数 (上記の例では4ブロック)に満たない場合でも一定のブロック (上記の例では4ブロック)が割り当てられる。フォルダについても、1つのフォルダにつき一定のブロック (上記の例では4ブロック)が割り当てられる。
以上のような理由から、各フォルダには4ブロック、各ファイルにも4ブロックづつが割り当てられて、合計で24ブロックとなっている。
ファイルの閲覧#
ターミナル環境上では、テキストファイル であれば内容を確認することができる。ここでテキストファイルと述べたのは、文字情報のみで構成されているファイルのことで、
プログラムのソースコード (
*.pyなど)HTMLファイル (
*.html)CSVファイル (
*.csv)
などが該当する。
テキストファイルでないファイルは バイナリファイル と呼ばれ、
画像ファイル (
*.jpgや*.pngなど)動画ファイル (
*.mp4など)PDFファイル (
*.pdf)
などがある。これらのバイナリファイルは、ターミナル上で内容を確認することはできず、後述する cat コマンドにバイナリファイルを指定すると、無意味な文字列が大量に表示される。
なお、Microsoft WordやExcelなどのファイルは一見文字情報だけが含まれているファイルではあるが、その実態はバイナリファイルであり、ターミナル上で内容を確認することはできないので注意してほしい。
fileコマンド#
file コマンドは、引数に指定したファイルの種類を判別して表示するコマンドである。例えば、data/fruits.txt というファイルがテキストファイルであることを確認するには、以下のように入力する。
$ file data/fruits.txt
data/fruits.txt: ASCII text
ここでは ASCII text がファイルの種類を表していて、ASCIIの文字コード (アルファベットと英数字) だけを含むテキストファイルであることを示している。
日本語が書かれているテキストファイル (以下の例ではMarkdown形式のファイル) の場合には、次のように表示される。
$ file README.md
README.md: Unicode text, UTF-8 text
この出力は、ファイル自体はテキストファイルではあるが、その内容がUnicodeと呼ばれる文字コードで書かれていることを意味している (Unicodeについては 正規表現の基礎 で詳細に扱う)。
では、次にバイナリファイルとして images/sunflower.jpg という画像ファイルを file コマンドで確認してみよう。
おそらく、以下のような出力が得られるはずである。
$ file images/sunflower.jpg
images/sunflower.jpg: JPEG image data, Exif standard: [TIFF image data, big-endian, direntries=16, height=2848, bps=0, PhotometricInterpretation=RGB, manufacturer=NIKON CORPORATION, model=NIKON D90, orientation=upper-left, width=4288], baseline, precision 8, 2048x1360, components 3
このように画像ファイルに対しては、JPEGというファイル形式だけでなく、画像のサイズやEXIF情報と呼ばれる撮影したカメラの情報なども表示されている。
練習問題
images/sunflower.jpgの拡張子 (.jpg)に変えたうえで、file コマンドを実行するとどうなるか確認せよ。
catコマンド#
ファイル内容の単純な確認によく用いられるのが cat (concatenate) コマンドである。cat コマンドは引数として渡された1つ、あるいは複数のファイルの内容を続けて表示する。
例えば、data ディレクトリに移動した上で fruits.txt の内容を確認してみると、次のようになる。
$ cat fruits.txt
apple
banana
orange
grape
apple
pineapple
banana
同様にして、fruits.txt と numbers.txt の両方の内容を続けて表示することもできる。
$ cat fruits.txt numbers.txt
apple
banana
orange
grape
apple
pineapple
banana
10
20
30
40
50
このように、ファイルを複数指定することで、そのファイルの内容を「連結 (concatenate)」したようにして表示できるので cat という名前がついている。
moreコマンドとlessコマンド#
cat コマンドでもファイルの内容を表示はできるのだが、ファイルの内容が多い場合には、画面に表示しきれず、結果として上の方に何が書かれているのか分からなくなるという問題がある。
そのような場合には more コマンドや less コマンドを使用するのが良い。これらのコマンドは、1画面分ずつ内容を表示し、スペースキーや矢印キーを押すことで次の画面に進むことができる。
more と less は非常に似た機能を持つコマンドではあるが、more コマンドがファイル全体を読み取ってから表示を開始するのに対し、less コマンドは表示に必要な分だけを逐一読み出していくなど、less の方が高機能であるため、一般的には less コマンドが良く用いられる。
less コマンドでファイルの内容を確認する場合、元のターミナル環境に戻るにはアルファベットのq を押せば良い。
headコマンドとtailコマンド#
ファイルの内容を確認する場合、実際に全体を見る前段階として、ファイルの最初の数行や最後の数行だけを確認したい場合がある。
このような場合に使うのが head と tail で -n 10 のようにオプションをつけることで、引数に与えたファイルの先頭や末尾の数行だけを表示できる。
$ head -n 3 data/fruits.txt
apple
banana
orange
$ tail -n 3 data/fruits.txt
apple
pineapple
banana
wcコマンド#
ファイルの内容を確認する以外にも、ファイルに含まれる行数や単語数、文字数を数えることもできる。これには wc (word count) コマンドを使用する。
wc コマンドは、引数にファイルを取り、オプションとして -l (line)、-w (word)、-c (character) のいずれかを指定することで、行数、単語数、文字数をそれぞれ数えることができる。
# 行数をカウント
$ wc -l fruits.txt
7 fruits.txt
# 単語数をカウント
$ wc -w fruits.txt
7 fruits.txt
# 文字数をカウント
$ wc -c fruits.txt
49 fruits.txt
練習問題
wcコマンドを用いてファイルの文字数を数えた場合と、実際のファイルの文字数を数えた場合とでは、どのような理由から、どのような違いが生じるか?
その他のファイル操作コマンド
ファイルの基本的な操作を行うコマンドは他にも多く存在する。本稿では紹介しきれなかったが、非常によく用いられるコマンドには以下のようなものがある。
touch: 空のファイルを作成するcp: ファイルやディレクトリをコピーするmv: ファイルやディレクトリを移動する (名前の変更も可能)rm: ファイルを削除するrmdir: 空のディレクトリを削除する (中身がある場合は削除できない)
検索#
デスクトップ環境でコンピュータを使っているときも、ファイルの名前や中身を検索したいことがあると思う。ターミナル環境でも同様に、コマンドを用いてファイルの名前や中身を検索することが可能である。
findコマンド#
まずは、ファイルの名前による検索を行う find コマンドについて見ていこう。find コマンドは指定したディレクトリ以下に存在する全てのファイル・フォルダの中から、オプションで指定された条件に合致するものを探し出すコマンドである。
特にオプションを指定せずにカレントディレクトリを表すドット (.) を引数に指定して find コマンドを実行すると、カレントディレクトリ以下に存在する全てのファイル・フォルダが表示される。
$ find .
(非常に多くのファイル・フォルダが表示される)
この中から、ファイルだけを取り出す場合には -type f を、ディレクトリだけを取り出す場合には -type d を指定する。
$ find . -type f
(非常に多くのファイルが表示される)
$ find . -type d
(非常に多くのディレクトリが表示される)
次に、名前に基づいてファイルを検索するには -name オプションを使用する。例えば、名前に .txt を含むファイルを検索するには、次のように入力すれば良い。
$ find . -type f -name "*.txt"
./data/fruits.txt
./data/numbers.txt
./data/romeo_and_juliet.txt
ここで指定した *.txt のアスタリスク (*) は ワイルドカード と呼ばれ、任意の文字列にマッチすることを意味している。例えば、a*.txt と指定すれば、a で始まり .txt で終わるファイル名にマッチする。
grepコマンド#
grep コマンドは後述するパイプと組み合わせて使われることが多いコマンドだが、基本的な使い方はファイルの中から特定の文字列を含む行を検索することである。
例えば data/fruits.txt の中から、apple という文字列を含む行を検索するには、以下のように入力すれば良い。
$ grep apple data/fruits.txt
apple
apple
pineapple
このように、fruits.txt の中には apple という文字列を含む行が3つ存在することが確認できる。
より厳密に apple という単語だけを含む行を検索したい場合には -w オプションをつければ良い。
$ grep -w apple data/fruits.txt
apple
apple
また、grep は1行に apple apple のように複数回 apple が含まれる場合でも、その行を1回だけ表示する。もし、1行に複数回 apple が含まれる場合に、その回数分だけ表示したい場合には -o オプションをつければ良い。
なお、コマンド名の grep は global regular expression print の略であり、正規表現の基礎 で学ぶ正規表現を用いれば、より柔軟な検索も可能である。
ヘルプの確認
ターミナル環境には多くのコマンドが用意されており、そのそれぞれは非常に多くのオプションを持つ。従って、それらを一度に覚えるのは一概に言って難しい。
コマンドの使用方法が分からなくなった時には、ヘルプを確認する習慣をつけるのが良いだろう。通常のコマンドは --help や -h などのオプションを付けることでヘルプが表示される。また、man grep のように man (manual)コマンドを用いることで、より詳細な使用方法を確認することもできる。
この際、-h, --help, man のそれぞれで、どのくらいの詳細度のヘルプが表示されるかはコマンドによって異なっている (ls のように -h ではヘルプが表示されないコマンドもある) ので注意してほしい。
2.3. リダイレクトとパイプライン#
ここまでターミナル環境で様々なコマンド実行すると、その結果がテキストとしてターミナルに表示されることを確認してきた。このようにターミナル上に結果を表示することを 標準出力 (standard output) と呼ぶ。
このようなコマンドの実行結果の出力先は、必ずしも標準出力 (= ターミナル)でなくともよく、ファイルに保存したり、他のコマンドに渡したりすることもできる。特に、コマンドの実行結果をファイルに保存することを リダイレクト (redirection) と呼び、コマンドの実行結果を他のコマンドに渡すことを パイプライン (pipeline) と呼ぶ。
リダイレクト#
リダイレクトを用いて、標準出力をファイルに保存するには、コマンドの後に > 記号を続けて、その後に出力先のファイル名を指定すれば良い (リダイレクトを行うとファイルの内容が上書きされるので注意すること)。
前述の cat コマンドを用いて data/fruits.txt と data/numbers.txt の内容を連結したものを data/combined.txt というファイルに保存するには、以下のように入力すれば良い。
$ cat data/fruits.txt data/numbers.txt > data/combined.txt
実際に、 combined.txt の内容が正しく保存されているかは、再度 cat コマンドを用いれば確認できる。
また、リダイレクトの際に > ではなく >> を用いると、指定したファイルの末尾に標準出力の内容を追記することもできる。
$ echo 60 >> data/combined.txt
このようなリダイレクトは、自分で作成したプログラムに対しても実行することができる。例えば、fizzbuzz.py という名前のPythonプログラムを実行すると、
$ python fizzbuzz.py
N = 100
1
2
fizz
4
buzz
fizz
7
8
(以下略)
のように表示されるが、この結果を log.txt というファイルに保存するなら
$ python fizzbuzz.py > log.txt
のように書けば良い。さて、ここで、log.txt の内容を確認してみると、
$ cat log.txt
1
2
fizz
4
buzz
(以下略)
のようになっていることが分かる。つまり、先ほど fizzbuzz.py の実行時に先頭に表示されていた N = 100 という行はリダイレクトされていないことが分かる。なぜ、このようになるか fizzbuzz.py の中身を確認してみよう。
N = 100 という表示を行っている行は次の行である。
print(f'N = {N:d}', file=sys.stderr)
この行は通常のprint 関数を呼び出しているが、 file というキーワード引数に sys.stderr が指定されている。この sys.stderr は 標準エラー出力 (standard error) を表しており、標準出力 (明示的に指定する場合にはsys.stdout)とは別の出力先である。
通常、プログラムを実行するときには、結果として表示したい出力と、ログなどの確認用に表示したい出力が分かれていることが多いため、標準出力と標準エラー出力の2つの出力先が用意されている。
標準エラー出力を無視して、標準出力だけを表示したい場合には、標準エラー出力を /dev/null という特別なファイルにリダイレクトする。この際、標準エラー出力をリダイレクトするには、> の代わりに 2> を用いれば良い (標準出力のリダイレクトを明示的に 1> と書くこともできる)。
$ python fizzbuzz.py 2> /dev/null
1
2
fizz
4
buzz
(以下略)
また、少々高度な使い方にはなるが、標準出力と標準エラー出力を異なるファイルにリダイレクトしたり、両方を同じファイルにリダイレクトすることもできる。
# 別のファイルへのリダイレクト
$ python fizzbuzz.py 1> log.txt 2> error.txt
# 同じファイルへのリダイレクト
$ python fizzbuzz.py > log.txt 2>&1
パイプライン#
パイプは、とあるコマンドの標準出力を、別のコマンドの入力 (より厳密には標準入力)にして連結するものである。パイプを用いるには、連結するコマンドの間に | を入力する。
例えば、冗長な使い方にはなるが cat コマンドを用いて data/fruits.txt の内容を表示し、その内容を grep コマンドに渡して apple という文字列を含む行を取り出すとすると、次のようになる。
$ cat data/fruits.txt | grep apple
apple
apple
pineapple
このようなコマンドの連結を行うと、様々な処理を、1行のコマンドで実行できるようになる (このような1行のコマンドを ワンライナー (one-liner) と呼ぶ)。例えば、ファイルの行数をカウントするのに用いた wc -l コマンドを grep と組み合わせると、特定の文字を含む行が何行あるのかを調べることもできる。
$ cat data/fruits.txt | grep apple | wc -l
3
同じようにして、現在のディレクトリ以下に特定のファイルがいくつ存在するかを調べることもできる。
$ find ./data -type f -name "*.txt" | wc -l
3
ここまでの実行例から分かることは、パイプラインで繋げられたコマンドは、前のコマンドの実行結果を含んだ テキストファイル を次のコマンドの引数に渡しているという点である。
つまり、
$ cat data/fruits.txt | grep apple | wc -l
というコマンドは、次の3つのコマンドに分解できる。
$ cat data/fruits.txt > temp1.txt
$ grep apple temp1.txt > temp2.txt
$ wc -l temp2.txt
このように、パイプラインが、前のコマンドの実行結果を一時ファイルとして次のコマンドに渡していることを意識しておくと、パイプラインを用いたコマンドの動作を理解しやすくなる。
練習問題
data/romeo_juliet.txt というファイルには、シェイクスピアの『ロミオとジュリエット』の全文が含まれている。このファイルに対して、以下の問いに答えよ。
"Romeo", "Juliet"という単語はそれぞれ何回ずつ出現しているか?
"Romeo" という単語が最後に登場する行には、何が書かれているか?
それぞれの解答とともに、その解答を得るために用いたコマンドも示しなさい。