10. 深層学習による画像識別#
前回、特徴量抽出では、画像から特徴量を検出し、それを画像識別に利用する方法を見てきた。
2000年台まで、画像識別の分野では、画像を如何に特徴化するかと得られた特徴からどのように物体を認識するかという二つの研究が中心となってきた。
そのために、SIFTを始めとする特徴量の改善や、カーネル法を用いたSVMの性能改善などが試みられてきたが、その性能は徐々に頭打ちになっていく。
そんな折、彗星のごとく現れた技術がニューラルネットワークを多層化した深層学習である。実は、ニューラルネット自体は人間の脳のシナプス同士の結合を模したモデルとして1950年代から研究されていた。
最初にニューラルネットが日の目を見たのは1980年代で、この頃には、入力層、隠れ層、出力層の三層を持つニューラルネットがある程度の性能を出せることが知られていた。当然ながら、その当時も、より多層のニューラルネットワークを利用しようという考え自体はあり、検討が試みられたが、ニューラルネットワークの持つ多数のパラメータを上手く最適化する手法がなく、その時代には実現が難しいと考えられていた。
なお、多層のニューラルネットの考え方を最初に提唱したのは、当時NHKの放送技術研究所の研究員であった福島邦彦氏であるとされており、その論文は、驚くべきことに1980年に出版されている [Fukushima, 1980]。方向性は異なるものの、これは2024年にノーベル物理学賞を獲得したJeffery Hinton氏の代表研究である誤差逆伝搬の論文[Rumelhart et al., 1986]や、John Hopfield氏のHopfieldネットワーク[Hopfield, 1982]の論文よりも前の研究である。
2010年代に入ると、それまで下火だったニューラルネットが再び注目を集めることになる。それまで細々と続けられていたニューラルネットワークの研究の中で、パラメータの過学習や、最適化時の勾配消失といった問題が徐々に解決されるとともに、GPUを用いた汎用計算であるGPGPU (General Purpose Computing on GPU)により並列計算の公立が大幅に上昇するなど、ニューラルネットワークを取り巻く環境が徐々に変化してくる。
そして、2012年に深層学習を一躍有名にする出来事が起こる。
ImageNetと呼ばれる大規模画像データセットの識別チャレンジであるILSVRC (ImageNet Large Scale Visual Recognition Challenge)において、トロント大学のGeoffrey Hintonらの研究チームが、AlexNet (筆頭著者のfirst nameから)と呼ばれる二股のニューラルネットを用いて、2位のエラー率26.2%に大差をつけ、エラー率わずか17.0%を達成し、優勝する [Krizhevsky et al., 2012]。この時の2位のチーム(東京大学のチーム)が用いた手法はSIFT, Fisher Vector, SVMを組み合わせたものであった。
この優勝を皮切りに、2013年の大会ではオックスフォード大学のチームがVGGというネットワークで2位に入り、以後、2014年はGoogleのチームがGoogLeNetというネットワークで2位、2015年はMicrosoftのチームがResNetというネットワークで優勝する。
こうして、2016年くらいになると、現在のニューラルネットワークの構築において一般的になっている諸技術、例えば、
Rectified Linear Unit (ReLU)
Max Pooling
Dropout
Batch Normalization
Skip Connection (Residual Block)
Adaptive Momentum Estimation (Adam)
などの技術が、一通り出そろう。
さらには、この頃になるとNVIDIAのCaffeや、モントリオール大学のtheano、FacebookのTorch、そしてPreferred NetworkのChainerといった汎用の深層学習用ライブラリが多数登場する。これによって、深層学習の研究が一気に花開き、現在に至る。
Google Colab用の準備
You are running the code in the local computer.
平仮名データセットの準備
10.1. PyTorchの基本#
本項では、数ある深層学習のフレームワークのうち、研究開発目的に最も一般的に使用されていると思われるPyTorchを扱う。
PyTorchには、いくつかのモジュールが用意されており、代表的なものが、
torchtorch.nntorch.nn.functional
の3つである。慣例的に、これらをこのような形でエイリアスを与えてインポートする。
# PyTorchのモジュール群
import torch
import torch.nn as nn
import torch.nn.functional as F
torchモジュールがテンソルデータそのもの(torch.Tensor等)や、データに対する操作 (torch.expやtorch.transpose等)が含まれる。
torch.nnモジュールには、ニューラルネットワークを構成するレイヤー (nn.Linearやnn.Conv2d等)や損失関数 (nn.CrossEntropyLossやnn.MSELoss等)が含まれる。
torch.nn.functionalモジュールには、torch.nnモジュールに含まれるクラス定義に対応する関数が用意されている。例えばnn.Linearに対応する関数としてF.linear、nn.MSELossに対応する関数としてF.mse_loss、といった具合である。
また、インストールすることは必須ではないが、PyTorchに付属するライブラリにTorchVisionがある。TorchVisionは、主にコンピュータ・ビジョンへの応用を目的とした補助関数が多数用意されている。
これ以外にも、有名ネットワークモデルの学習済み重みなどが提供されており、AlexNetやResNet50等のほか、ViTなどの比較的新しいものも含まれている。
本資料では、画像の前処理に使うtransformsモジュールだけを用いる (使用方法については後述する)。
10.1.1. torch.Tensor#
PyTorchの中で変数を扱う場合、スカラーであってもベクトルであっても、はたまた行列であっても、共通でtorch.Tensorという型を用いる。これは、NumPyのnp.arrayとほとんど同じように使うことができる。
初期化をする方法には、いくつかあるが、大きく分けて、
torch.Tensorのコンストラクタを呼び出すtorch.tensor関数を用いてTensorを作るNumPyの配列を最初に用意して
torch.from_numpy関数を使う
の3つの方法がある。順に見ていこう。
torch.Tensorを使う#
まず、torch.Tensor型のコンストラクタを用いて初期化する場合を見ていく。この場合、コンストラクタの引数にPythonやNumPyの配列を指定して初期化する。
この時、配列がどのような型であっても、PyTorchのdefault_dtypeに指定された型 (初期値はfloat32)の型にキャストされる。
x_npy = np.arange(10)
print("NumPy's dtype:", x_npy.dtype)
x = torch.Tensor(x_npy)
print("Torch's dtype:", x.dtype)
NumPy's dtype: int32
Torch's dtype: torch.float32
このように、NumPyの配列としての型はint64型であるにも関わらず、torch.Tensorを用いることで、型がfloat32に変更されていることが分かる。なお、この初期の型はtorch.set_default_dtyoeで変更することもできる。
# 初期の型を64bit浮動小数に変更
torch.set_default_dtype(torch.float64)
x = torch.Tensor(x_npy)
print("Torch's dtype:", x.dtype)
# 元に戻しておく
torch.set_default_dtype(torch.float32)
Torch's dtype: torch.float64
torch.tensorを使う#
次にtorch.Tensor型のインスタンスを作成する関数であるtorch.tensorを用いる場合を見ていく。
本関数はtorch.Tensorと関数が似ており、非常に紛らわしいが、torch.Tensorはコンストラクタであり、torch.tensorは初期化用のユーティリティ関数である。
使い方も非常に似ており、torch.tensorにも、PythonやNumPyの配列を指定してtorch.Tensor型の多次元配列を作ることができる。
x_npy = np.arange(10)
x = torch.tensor(x_npy)
print("Torch's dtype:", x.dtype)
Torch's dtype: torch.int32
torch.tensorは先ほどとは異なり、PythonやNumPyの配列で定義されている要素の型を引き継ぐ。そのため、上記の例ではtorch.Tensorのdtypeがint64になっている。また、torch.tensor関数は、型を指定してtorch.Tensorを作ることもできる。
x = torch.tensor(x_npy, dtype=torch.float32)
print("Torch's dtype:", x.dtype)
Torch's dtype: torch.float32
また、詳細については後述するが、PyTorchの自動微分の機能を使うために必要なrequires_gradパラメータを指定することもできる。
x = torch.tensor(x_npy, dtype=torch.float32, requires_grad=True)
print(x)
tensor([0., 1., 2., 3., 4., 5., 6., 7., 8., 9.], requires_grad=True)
このようにtorch.tensor関数はtorch.Tensorのコンストラクタを呼び出す場合と比べて圧倒的に使い勝手が良い。
従って、プログラマ自身が型を管理することに抵抗がないのであれば、torch.tensor関数を使うのが良いだろう。
torch.from_numpy#
最後にNumPyの配列からtorch.Tensor型のインスタンスを作成するtorch.from_numpyを用いる場合を見ていく。
torch.from_numpy関数もtorch.Tensorと仕様はかなり似ているが、
引数としてNumPyの配列しか取ることができない
dtypeはNumPyのものを引き継ぐ
の2点が大きく異なる。
x_npy = np.arange(10)
x = torch.from_numpy(x_npy)
print("Torch's dtype:", x.dtype)
Torch's dtype: torch.int32
またtorch.from_numpyは元のNumPyの配列とデータを共有しており、元の配列の値を書き換えるとそれが反映されるという違いがある。
# torch.Tensorの場合
x_npy = np.arange(10)
x = torch.Tensor(x_npy)
print('Before:', x)
x_npy *= 2
print(' After:', x)
Before: tensor([0., 1., 2., 3., 4., 5., 6., 7., 8., 9.])
After: tensor([0., 1., 2., 3., 4., 5., 6., 7., 8., 9.])
# torch.from_numpyの場合
x_npy = np.arange(10)
x = torch.from_numpy(x_npy)
print('Before:', x)
x_npy *= 2
print(' After:', x)
Before: tensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=torch.int32)
After: tensor([ 0, 2, 4, 6, 8, 10, 12, 14, 16, 18], dtype=torch.int32)
この違いを意識すべき場面は少ないが、時に問題が生じることがあるので、特段の理由がない限りはtorch.tensorを使う方が、多くの場合で問題を引き起こす危険性が低いだろう。
10.1.2. torch.Tensorからの値の取り出し#
またtorch.Tensor型で何らかの演算を行った後で、それをPythonやNumPyの配列に戻したいと思うこともあるだろう。この場合には、Pythonの配列ならtolist関数、NumPyの配列ならnumpy関数を用いる。
x = torch.arange(10)
# Pythonの配列に直す
x_list = x.tolist()
print('Type:', type(x_list))
print(x_list)
# NumPyの配列に直す
x_npy = x.numpy()
print('Type:', type(x_npy))
print(x_npy)
Type: <class 'list'>
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Type: <class 'numpy.ndarray'>
[0 1 2 3 4 5 6 7 8 9]
また、配列の値が1つである場合に限り、item関数を使って、その1つの値をPythonの数値型として取り出すこともできる。このitem関数は、要素が2つ以上ある配列に対して呼び出すと例外が発生するので注意すること。
x = torch.tensor([1.0], dtype=torch.float32)
print(x.item())
1.0
10.2. 自動微分#
深層学習を支える重要な技術に自動微分がある。関数の微分は、損失関数の最小化といった最適化問題にとって重要な情報であり、例えば、最急降下法やニュートン法といったアルゴリズムは、それぞれ関数の1階微分 (勾配)と、2階微分 (Hesse行列)を用いる。
しかし、このような微分を求めるには、数学的に関数の微分を求めておく必要があり、特に関数が複雑な場合には、それを求めることは困難である (従来はMathematicaなどのソフトを使って、勾配を求めるコードを書き出していた)。
また、1階微分であれば、差分法によって近似をすることも可能ではあるが、数値精度の問題は残る。2階微分以上になると差分計算の誤差が蓄積していくため、数値的に満足な結果を得ることは非常に難しくなる。
10.2.1. 自動微分の仕組み#
自動微分は、プログラム的に、とある演算とその微分計算がペアとして定義されており、演算の列によって表される関数の微分は、各演算の微分から、合成関数の微分としての連鎖率 (chain rule)により計算される。
一例として、ここでは、
の微分を例にとって見てみよう。
ここで、\(g(x) = x^2\), \(h(x) = \cos x\)とすると、\(f\)は\(g\)と\(h\)の合成関数として\(f = h \circ g\)と表せる。言うまでもなく、\(f\)の微分\(f'\)は、\(h\)と\(g\)の微分を用いて、
となる。ここで注目してほしいのは、\(f(x)\)を計算する際の計算順序が、
\(x\)の値が与えられる
\(y = x^2\)の値を計算する
\(z = \cos(y)\)の値を計算する
となっているということである。導関数\(f\)の微分を計算するときには、この逆順に、
\(z\)の\(z\)に関する微分として\(\text{d}z/\text{d}z=1\)が与えられる
既知の\(y\)から\(\text{d}z/\text{d}y = (\text{d}z/\text{d}z) \cdot (\text{d}z/\text{d}y) = 1 \cdot (-\sin(y)) = -\sin(y)\)を計算する
既知の\(x\)から\(\text{d}z/\text{d}x = (\text{d}z/\text{d}y) \cdot (\text{d}y/ \text{d}x) = (-\sin(y)) \cdot (2 x) = -2x \sin(x^2)\)を計算する
という流れになっている。従って、各演算\(y=f(x)\)において、
演算の入力\(x\)を保持しておく
演算の導関数\(\text{d}y/\text{d}x\)を定義しておく
という準備をしておけば、最終出力\(z\)の\(y\)に関する微分\(\text{d}z/\text{d}y\)が与えられれば、連鎖率を用いて\(\text{d}z/\text{d}x\)が求まる、という訳である。
10.2.2. 自動微分の利用#
では、上記の議論をPyTorchを用いて実験してみる。前述の通り、torch.tensor関数にrequires_gradパラメータを指定することで、自動微分により勾配が計算される変数を作ることができる。
# 変数を作成
x = torch.tensor([2.0], requires_grad=True)
なお、一度、作成したTensorに対して自動微分を有効にしたい場合にはrequires_grad_関数にTrueを渡す。
x = x.requires_grad_(True)
それでは、ここで定義した\(x\)を用いて変数を用いて、\(z = \cos(x^2)\)を段階的に計算してみる。
# y = g(x) = x^2の計算
y = x * x
print(f'y = g(x) = {y.item():.1f}')
# z = cos(y)の計算
z = torch.cos(y)
print(f'z = h(y) = {z.item():.5f}')
y = g(x) = 4.0
z = h(y) = -0.65364
最終的な\(z\)の\(x\)に関する微分を求めるには、z.backward()という関数を呼び出せば良い。ただし、この関数はスカラーの出力にしか使えないので注意が必要。
# 微分の計算
z.backward()
すると、予め自動微分を有効にしておいた変数にはgradというメンバが追加され、そこに微分の値が代入される。なお、backward関数は、デフォルトでは、一度呼び出すと同じ変数に対して再度呼び出すことはできないようになっている(メモリをできるだけ削減するため)。
同じ関数に対して、何度もbackwardを呼び出したい場合には、backward関数のパラメータにretain_graph=Trueを渡すこと (例外のメッセージにも同様のことが書かれている)。
try:
z.backward()
except Exception as e:
print('Exception:', e)
Exception: Trying to backward through the graph a second time (or directly access saved tensors after they have already been freed). Saved intermediate values of the graph are freed when you call .backward() or autograd.grad(). Specify retain_graph=True if you need to backward through the graph a second time or if you need to access saved tensors after calling backward.
dzdx_autograd = x.grad
print(f'autograd: dz/dx = {dzdx_autograd.item():.5f}')
dzdx_analytic = -2.0 * x * torch.sin(x * x)
print(f'analytic: dz/dx = {dzdx_analytic.item():.5f}')
autograd: dz/dx = 3.02721
analytic: dz/dx = 3.02721
以上から、自動微分によって、正しく演算の微分が計算できていることが確認できた。
上記と同等の計算は、単に入力となっている\(x\)に関する勾配を求めたいだけであれば torch.autograd.gradを用いて、以下のように書くこともできる。なお、torch.autograd.grad関数の戻り値は、配列になっているので注意すること。
x = torch.tensor([2.0], requires_grad=True)
z = torch.cos(x * x)
dzdx = torch.autograd.grad(z, inputs=x)
print(f'autograd.grad: dz/dz = {dzdx[0].item():.5f}')
autograd.grad: dz/dz = 3.02721
計算グラフ
上記の計算では、 \(y = x^2\), \(z = \cos(y)\) として、連鎖律を用いて微分の計算を行った。このように、「ある計算の結果」を「次の計算で用いる」というような、計算の繋がりによって作られるグラフ構造のことを計算グラフと呼ぶ。通常、四則演算や関数の計算などの多くの計算は単項演算 (変数1つに対して行われる演算、 \(x^2\) や \(\cos(x)\) など)と二項演算 (変数2つに対して行われる演算、 \(x + y\) や \(x^y\) など)に分けられ、3つ以上の変数が絡む演算も基本的には単項演算と二項演算の組み合わせによって表現できる。
自動微分においては、計算の過程でこのような計算グラフをライブラリが内部的に構築しており、グラフを遡っていくことで、「最終的な出力」の「グラフ中に現れた変数」に関する微分を計算している。PyTorchのbackward等の関数に渡せるパラメータの中にもretain_graphやcreate_graphなど、「グラフ」という言葉を含むものがあるのはこのためである。
10.2.3. 自動微分可能な演算の定義#
PyTorchを使うと、自分で微分可能な演算を定義することもできる。関数を定義するための一般的な方法は、torch.autograd.Functionを継承したクラスを定義し、そこに静的メソッドとしてforwardとbackwardの二つの関数を実装するというものである。
forward内で計算済みの変数で、backwardの計算でも使うものはctx.save_for_backward(...)を用いてbackward関数に渡すことができる。変数の取り出しにはctx.saved_tensorsを用いる。以下の例では、\(\cos(x)\)を例にとって、実際に微分可能な演算を定義してみる。
from torch.autograd import Function
class MyCosine(Function):
@staticmethod
def forward(ctx, x):
y = torch.cos(x)
ctx.save_for_backward(x, y)
return y
@staticmethod
def backward(ctx, grad_output):
x, y = ctx.saved_tensors
return grad_output * (-torch.sin(x))
この実装では、forwardの中で、\(y = \cos(x)\)として、戻り値を計算した後に、入力の\(x\)と出力の\(y\)の値をsave_for_backward(x, y)としてbackward側でも使えるようにしている。今回の計算では、\(\cos(x)\)の微分が\(-\sin(x)\)であるため、必ずしも\(y\)をbackward側で使えるようにしておく必要はない。しかし、例えば\(\exp(x)\)やシグモイド関数\(1 / (1 + \exp(x))\)のように、導関数のなかに自分自身を含むようなものも多く、計算量の観点から、forwardでの出力をbackward側で使えるようにしておくことが多い。
このFunction型のサブクラスはMyCosine.applyのように呼び出すことで関数のforwardが呼び出されて、その計算結果が使われた出力においてbackwardが呼び出されると、自動的にMyCosineのbackwardのその計算の中で呼び出されるようになる。
PyTorch内部の実装においては、上記のようなFunctionのサブクラスを内部で呼び出すような関数を定義している場合が多く、それに従ってmy_cos関数を定義しておく。
def my_cos(x):
return MyCosine.apply(x)
これを用いて、再度 \(\cos(x^2)\)の微分を計算してみると、以下のように正しく計算が行えていることが分かる。
x = torch.tensor([2.0], requires_grad=True)
y = x * x
z = my_cos(y)
z.backward()
print(f'my cosine: dzdx = {x.grad.item():.5f}')
my cosine: dzdx = 3.02721
問
torch.autograd.Functionのサブクラスとしてシグモイド関数を扱うクラスを実装してみよ。シグモイド関数の導関数は自分自身の値を用いて表せることに注意すること。
10.2.4. 二階微分の計算#
続いて、前述の\(f(x) = \cos(x^2)\)の二階微分\(f^{''}(x) = -2 \sin(x^2) - 4x^2 \cos(x^2)\)の計算を自動微分で行ってみる。
実は、自動微分を使えば、高階微分を計算することも容易で、二階導関数を求めたい場合、一階導関数の計算中に計算グラフを遡っていく計算に対して、別の計算グラフを構築すれば良い。この計算グラフを再度遡って微分を求めることで二階微分が求まる、というわけである。
例えば、先ほどの計算であれば、連鎖律の途中で、\(2x\)の計算や\(-\sin(x)\)の計算が発生していたが、これらの計算について、途中結果を保存し、その微分計算が行えるように計算グラフを構築することができる。なお、二階微分を計算するときにはbackward関数の代わりに、torch.autograd.gradを使わないと警告メッセージが出るので注意すること (計算自体はできる)。
x = torch.tensor([2.0], requires_grad=True)
y = x * x
z = torch.cos(y)
# 1階微分を計算しつつ, 新たな計算グラフを作成
dzdx = torch.autograd.grad(z, inputs=x, create_graph=True)
# 2階微分を計算
ddz_ddx_auto = torch.autograd.grad(dzdx, inputs=x)
ddz_ddx_analy = -2.0 * torch.sin(x**2.0) - 4.0 * x**2.0 * torch.cos(x**2)
print('autograd: ddz_ddx = {:.5f}'.format(ddz_ddx_auto[0].item()))
print('analytic: ddz_ddx = {:.5f}'.format(ddz_ddx_analy.item()))
autograd: ddz_ddx = 11.97190
analytic: ddz_ddx = 11.97190
このように、二階微分の場合も正しく計算できていることが分かる。以後、より高階な微分であってもtorch.autograd.gradの引数でcreate_graph=Trueを指定する限りは計算し続けることができる。
10.2.5. 多変数関数の微分#
続いては、変数が2つ以上の場合の微分 (勾配)について見てみる。今回は例としてReosenbrock関数と呼ばれる、以下の関数について微分を計算してみる。
この関数において\(a = 1\), \(b = 100\)とするとして、二次元平面上に値をプロットすると以下のようになる (カラーバーは対数の値に対して計算されている)。
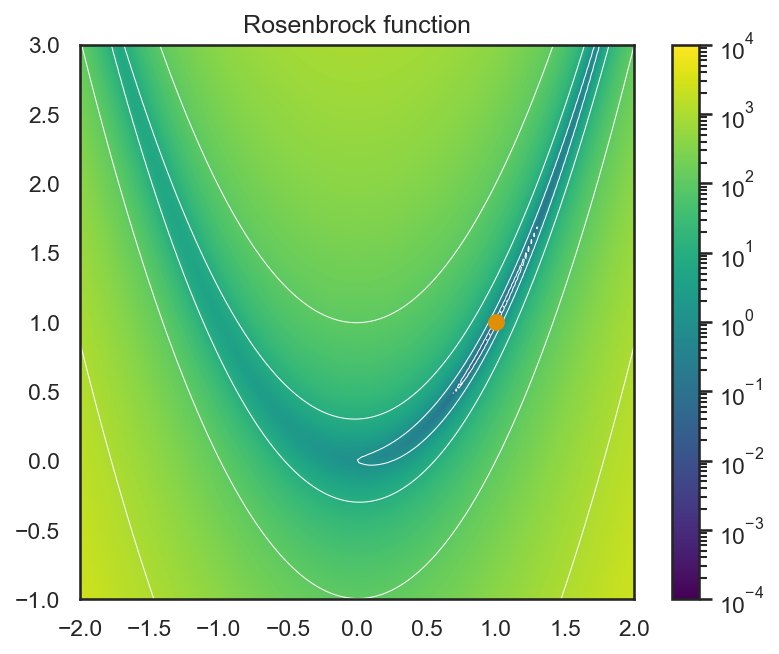
この関数は、\((1.0, 1.0)\)の点を打った場所が関数の最小値をとる箇所になっているのだが、最小値の近傍が非常に狭い谷のような形になっており、さらにその谷が放物線上に湾曲しているため、この赤点の位置の最小値を求めることが困難であるとされている。
まずは\((x, y) = (0, 0)\)として、Rosenbrock関数自体の値を計算してみる。
x = torch.tensor([0.0, 0.0], requires_grad=True)
f = (x[0] - 1.0) ** 2.0 + 100.0 * (x[1] - x[0] ** 2.0) ** 2.0
print(f'f(0, 0) = {f.item():f}')
f(0, 0) = 1.000000
次に、単一の変数の場合と同様に、出力のfに対してbackwardを呼び出して、\(x, y\) (上記のコードではxの0番目と1番目の要素に対応)に関する微分を求める。
f.backward()
print(f'df/dx at (0, 0) = {x.grad.tolist()}')
df/dx at (0, 0) = [-2.0, 0.0]
Rosenbrock関数の\(x\), \(y\)に関する偏微分は、それぞれ
であるので、\(a = 1, b= 100\)かつ\((x, y) = (0, 0)\)であるとき、導関数の値は\((-2, 0)\)になっており、上記の自動微分による結果と一致する。
続いては、Rosenbrock関数の二階導関数としてのHesse行列 (Hessianとも言う)を求めてみる。この場合は、先ほどの1変数の場合よりは多少工夫が必要になる。
まずは、fに対してtorch.autograd.gradを計算する。
x = torch.tensor([0.0, 0.0], requires_grad=True)
f = (x[0] - 1.0) ** 2.0 + 100.0 * (x[1] - x[0] ** 2.0) ** 2.0
grad = torch.autograd.grad(f, inputs=x, create_graph=True)
安直には、このgradに対して、もう一度torch.autograd.grad関数を適用すれば良さそうだが、前述の通りbackward関数やtorch.autograd.grad関数は、出力がスカラー出ない場合には使うことができない。
try:
H = torch.autograd.grad(grad, inputs=x)
except Exception as e:
print('Exception:', e)
Exception: grad can be implicitly created only for scalar outputs
従って、ここで計算に一工夫が必要になる。ここで連鎖律の計算を思い出してほしい。連鎖律を計算するとき、スカラー値スカラー関数の場合には、\(\text{d}z / \text{d}z = 1\)から、連鎖律が始まり、その前の計算の微分を順に乗していくことで最終的な入力変数に関する微分を計算していたのであった。
この理屈で言えば、出力が二次元ベクトルであるような関数において、連鎖律のスタートとなるべき値は
の2つとなることに気づく。そこで、このそれぞれを連鎖律のスタートとしてgrad_outputsパラメータに指定してtorch.autograd.gradを呼び出してみる。
ddf_dxx = torch.autograd.grad(grad, inputs=x, grad_outputs=torch.tensor([1.0, 0.0]), retain_graph=True)[0]
ddf_dyy = torch.autograd.grad(grad, inputs=x, grad_outputs=torch.tensor([0.0, 1.0]), retain_graph=True)[0]
H = torch.stack([ddf_dxx, ddf_dyy], axis=0)
print(H)
tensor([[ 2., 0.],
[ 0., 200.]])
Rosenbrock関数のHesse行列は、解析的には
であるので、\(a = 1, b = 100\), \((x, y) = (0, 0)\)の時には、
となり、自動微分の結果が解析的な微分結果と一致していることが分かる。
10.3. ニュートン法の実装#
それでは、ここで練習としてニュートン法を用いてRosenbrock関数の最小値を求めてみよう。ニュートン法は、Hesse行列\(\mathbf{H}\)と、\(f\)の勾配\(\nabla f\)を用いて、
のように更新幅を計算するような、繰り返し最適化法の一種である。これは、関数\(f(\mathbf{x})\)の\(\boldsymbol\delta\)周りのTaylor展開により、
となることから説明できる。この式を変形すると、
という式が得られる。従って、Taylor展開の第2項までで元の関数を近似した範囲においては、\(\text{d} f / \text{d}\boldsymbol\delta = \mathbf{0}\)となるような場所に移動することで、関数の最小値に近づくことができる (これは、関数を局所的に二次関数で近似して、その二次関数の「底」に移動することに対応する)。
実際には、最小化すべき関数が局所的に二次関数で近似できることばかりではないので、通常は(10.1)で求まった更新方向に小さな定数\(\alpha\)を乗じて\(\mathbf{x}\)の値を
のように更新することが多い。
では、ここまでの議論を踏まえて、実際に自動微分により求めたHesse行列を用いてRosenbrock関数を最小化してみよう (以下にコードと実行結果を示すが、まずは自分自身で考えてみてほしい)。
def rosenbrock(x):
"""Rosenbrock function"""
return (x[0] - 1.0) ** 2.0 + 100.0 * (x[1] - x[0] ** 2.0) ** 2.0
initial_x = np.array([-1.0, 1.5])
def calc_newton_step(f, x):
grad = torch.autograd.grad(f, inputs=x, create_graph=True)[0]
gx = torch.autograd.grad(
grad,
inputs=x,
grad_outputs=torch.tensor([1.0, 0.0]),
retain_graph=True,
)[0]
gy = torch.autograd.grad(
grad,
inputs=x,
grad_outputs=torch.tensor([0.0, 1.0]),
retain_graph=True,
)[0]
H = torch.stack([gx, gy], axis=0)
return torch.linalg.solve(H, grad)
x = torch.tensor(initial_x, requires_grad=True)
pts = []
for i in range(100):
pts.append(x.detach().numpy())
fx = rosenbrock(x)
dx = calc_newton_step(fx, x)
x = x - 0.5 * dx
x = x.detach().requires_grad_(True)
print('The answer is:', x.detach().numpy())
The answer is: [1. 1.]
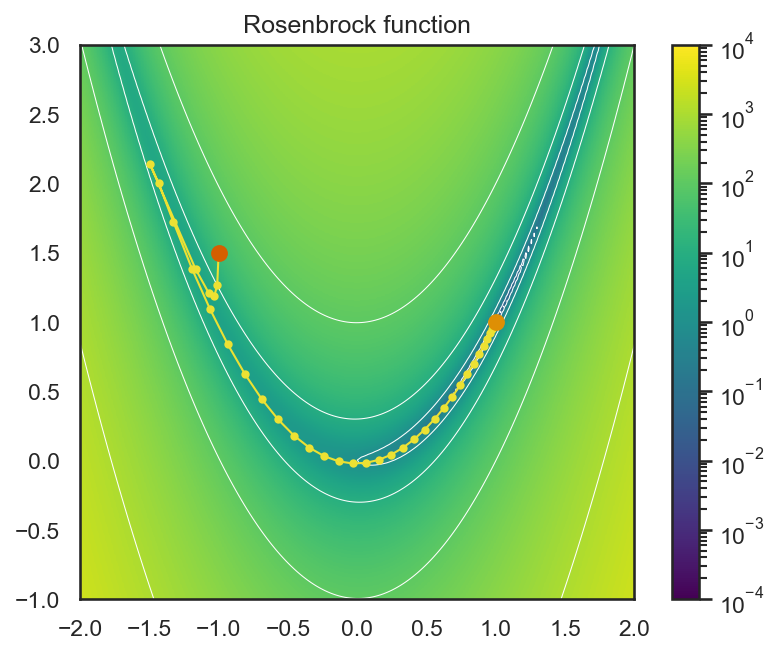
この図では、\((0.0, 0.0)\)の初期値から\((1.0, 1.0)\)の最小値に至るまでの最適化の過程をマーカー付きの曲線で示している。各マーカーの位置を見てみると、徐々に最小値に至るスピードが遅くなりつつも、正しく関数の最小値を取る箇所に収束していることが分かる。
Rosenbrock関数の最小化については、解の初期値やニュートン法のステップ幅を変化させることで、収束が不安定になって最小解からはずれて・近づいてを繰り返すような軌跡を描くこともある。ぜひ、いろいろなパラメータで軌跡を描画して、その性質の理解に努めて欲しい。
機械学習と損失関数
ここでは、関数の勾配を求めて、勾配法により関数を最小化する問題を解いた。深層学習は、ニューラルネットのパラメータを変数として、その変数を同じく勾配法により最適化する問題であり、最小化する関数は損失関数(loss function)と呼ばれる (反対に目的を達成するために最大化される関数を目的関数と呼ぶ)。
ニューラルネットのパラメータ最適化(=訓練)には、ニュートン法や準ニュートン法のような損失関数の二階微分を考慮するような方法を用いることは少なく (ただしAdaSecant[Gulcehre et al., 2014]のような二階微分を考慮する方法もある)、多くの場合は単純な確率的最急降下法やRMSprop, Adamのようなアルゴリズムが使われることが多い。これは、パラメータ数が多くなると、Hesse行列を求めるのに多くの計算量が必要になるためで、そうであれば、一階微分だけが求まれば実行できる最急降下法を安定化させるように工夫する方が良い、という発想である。
10.3.1. オプティマイザを利用した最適化#
PyTorchにはオプティマイザというモジュールが用意されており、一階微分量を用いる最急降下法を対象として、さまざまなアルゴリズムが提供されている。ニューラルネットワークの訓練においては、確率的に選ばれたミニバッチから、パラメータを更新する勾配を求めるので、モジュールの名前としては確率的最急降下法 (SGD = stochastic gradient descent)を基本としたものとなっている。
確率的最急降下法#
最も単純な確率的最急降下法では、誤差関数を\(\mathcal{L}\)、パラメータを\(\theta\)、更新のステップ幅 (=更新率)を\(\gamma\)として、パラメータ\(\theta\)を以下の式で更新する。
しかし、単純な確率的最急降下法はパラメータの更新方向が安定しないという問題があり、モメンタム(慣性)を使って、急激に勾配方向が変わらないように移動平均を取るアルゴリズム (Momentum SGD)もある。Momentum SGDの更新式は以下の通り (参照)。
このように、慣性パラメータとして\(\mu\) (\(0 < \mu < 1\))を導入することで、過去の更新方向を一定の割合で残しつつ、パラメータの更新を行う。
RMSprop#
最急降下法のもう一つの問題に解の振動が挙げられる。これはパラメータ更新のステップ幅が大きすぎるために、谷のような形状の両岸を行ったり来たりしてしまうような現象である。当然、ステップサイズを小さくすればその影響は抑えられるが、その分、最適化の収束は遅くなってしまう。
このような振動の問題を防ぐアルゴリズムの一つにRMSprop (root-mean-square propagation)がある。RMSpropは、その名前にある通り、勾配の二乗平均平方根を取り、その値が履歴として大きいパラメータの更新を抑制する。振動が起こっている時は、本来更新しなくても良い方向に行ったり来たりしてしまっているわけだから、このような過去の更新量に基づく調整が有効に働くことが分かるだろう。
RMSpropのパラメータ更新式は以下の通り (参考)。
この式が示すとおり\(v_{t}\)は、過去の勾配の二乗を時間平均したもので、その平方根の逆数を勾配\(g_t\)に乗ずることで、過去に多く更新されているパラメータの更新を抑制している。なお、\(\epsilon\)はゼロ除算を防ぐための定数でPyTorchでは初期値として\(1 \times 10^{-8}\)が設定されている。
Adam#
Adam (adaptive momentum method)は、前述のMomentum SGDとRMSpropを組み合わせたアルゴリズムで、確率的最急降下法の勾配方向の不安定性と振動の問題を両方解決するように設計されている。
Adamには更新率\(\gamma\)と合わせて、二つのパラメータ\(\beta_1\)と\(\beta_2\)を設定する。これらのうち\(\beta_1\)は、勾配方向に慣性を調整するパラメータで1に近い値を取るほど、強く慣性が働き、過去の勾配の影響を強く残す。一方、\(\beta_2\)は、振動の抑制に働くパラメータで、1に近い値が取るほど、過去の勾配の大きさを考慮して更新量を抑制するようになる。
また、これに加えて、\(\beta_1\), \(\beta_2\)を用いて、最適化の始めは大きなステップサイズで更新を行い、徐々にその効果を弱めていくという計算もなされている。
オプティマイザを使用した最適化#
深層学習では、上記のSGDやAdam等のオプティマイザを用いてニューラルネットワークのパラメータを最適化するのだが、この仕組みは最急降下法等の一階微分を用いる最適化問題にも使用することができる。
そこで、深層学習に進む前に、まずは前述のRosenbrock関数を上記のオプティマイザを使って最適化し、その違いについて見てみよう。
データローダとは、PyTorchを用いたニューラルネットワークの学習において、ミニバッチ学習を簡単にするための仕組みである。通常、深層学習には大量の訓練データが必要であり、それら全てを考慮したパラメータの更新方向(=勾配)を求めることは現実的ではない。
そこで、大量の訓練データから少数のデータ、すなわちミニバッチをサンプルし、そのミニバッチ内のデータによって与えられる勾配が、データ全体から求まる勾配の近似として十分に正しく動作することを仮定する。データから収集してくるミニバッチの数はtorch.utils.data.Dataset型のサブクラスとして用意されたデータセット・クラスを引数にとるtorch.data.utils.data.DataLoaderによって制御できる。
では、上記のひらがな73文字データセットについて、まずはデータの読み出しを行う役割を持つデータセット・クラスを作成してみよう。データセット・クラスはtorch.utils.data.Dataset型のサブクラスとして実装する。この際、コンストラクタと合わせて、データの総数を返す__len__関数と、データ1つをサンプルする__getitem__関数の二つを実装する。
# 比較するオプティマイザのリスト
optims = {
'SGD': lambda x: torch.optim.SGD([x], lr=2.0e-3),
'Momentum-SGD': lambda x: torch.optim.SGD([x], lr=2.0e-3, momentum=0.9),
'RMSprop': lambda x: torch.optim.RMSprop([x], lr=2.0e-3),
'Adam': lambda x: torch.optim.Adam([x], lr=2.0e-3),
}
# 各オプティマイザの軌跡を保存する
plots = {}
for name, opt in optims.items():
x = torch.tensor(initial_x, requires_grad=True)
optim = opt(x)
history = []
for i in range(10000):
# 現在の点を保存
history.append(x.clone().detach().numpy())
# パラメータの更新
y = rosenbrock(x)
optim.zero_grad()
y.backward()
optim.step()
plots[name] = np.array(history)
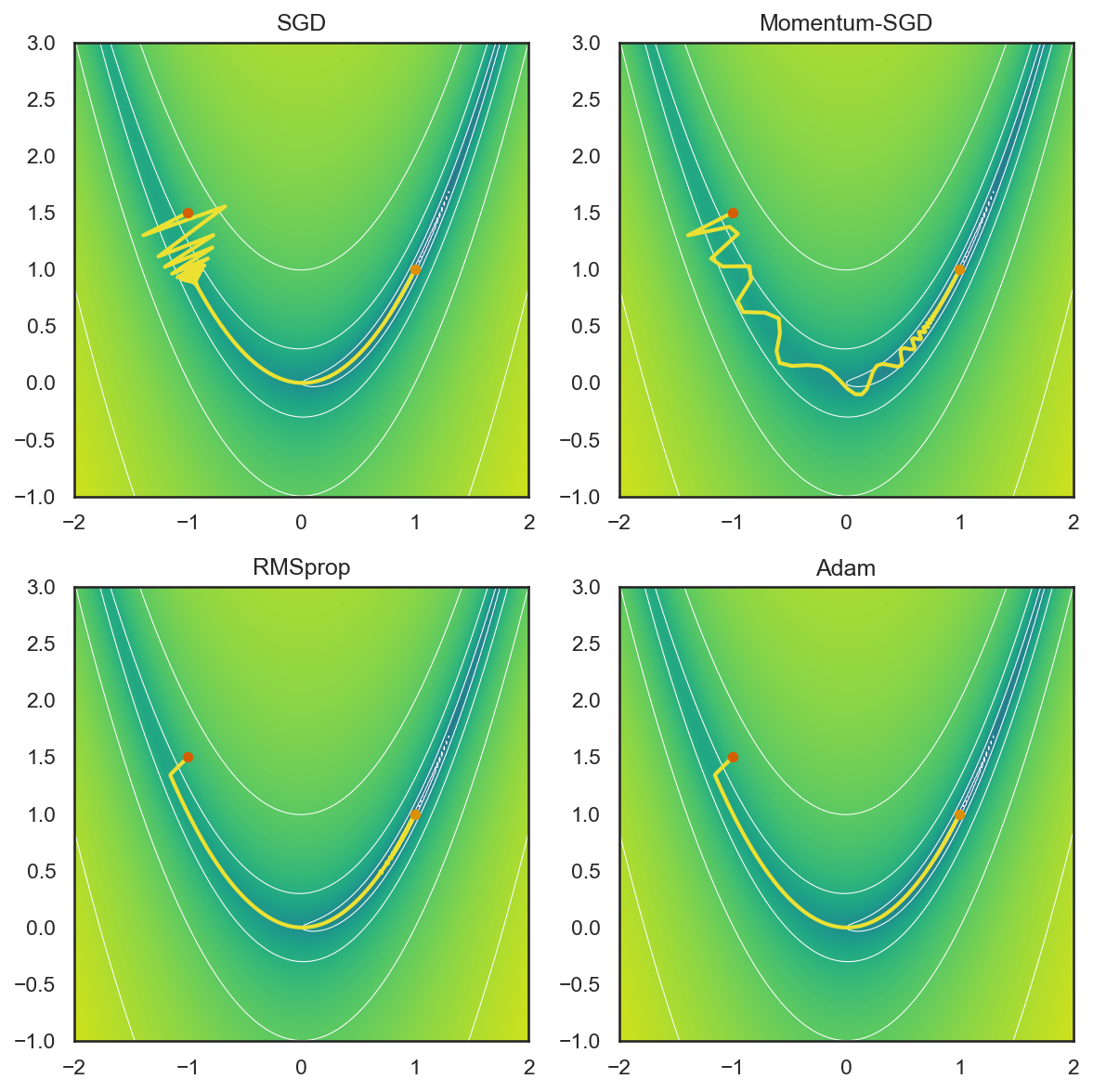
上記の結果を見てみると、SGDは最初の方で、解が大きく振動しているのに対して、Momentum SGDでは、それが多少緩和されていることが分かる。また、更新量から、その勾配を調整する仕組みが入っているRMSpropやAdamでは、ほとんど解が振動することなく、Rosenbrock関数の谷に沿って、解が収束している。
このような、最適化手法の性質の違いに留意しつつ、適切なオプティマイザを選ぶことが好ましい。ただし、オプティマイザに関しては、Adamの発展形などもいろいろと提案されており、新しいものを使おうとすると切りがないため、深層学習を使って研究する場合には、現在、他の多くの研究で用いられているものを使っておくのが無難だろう。
10.4. 深層学習#
PyTorchを使った深層学習をするために準備すべきことはいくつかある。以下では、
のそれぞれについて順に説明する。
10.4.1. データローダの作成#
データローダとは、PyTorchを用いたニューラルネットワークの学習において、ミニバッチ学習を簡単にするための仕組みである。通常、深層学習には大量の訓練データが必要であり、それら全てを考慮したパラメータの更新方向(=勾配)を求めることは現実的ではない。
そこで、大量の訓練データから少数のデータ、すなわちミニバッチをサンプルし、そのミニバッチ内のデータによって与えられる勾配が、データ全体から求まる勾配の近似として十分に正しく動作することを仮定する。データから収集してくるミニバッチの数はtorch.utils.data.Dataset型のサブクラスとして用意されたデータセット・クラスを引数にとるtorch.data.utils.data.DataLoaderによって制御できる。
では、上記のひらがな73文字データセットについて、まずはデータの読み出しを行う役割を持つデータセット・クラスを作成してみよう。データセット・クラスはtorch.utils.data.Dataset型のサブクラスとして実装する。この際、コンストラクタと合わせて、データの総数を返す__len__関数と、データ1つをサンプルする__getitem__関数の二つを実装する。
import numpy as np
from PIL import Image
from torch.utils.data import Dataset, DataLoader
class HiraganaDataset(Dataset):
"""
ひらがな46文字データセット
"""
CHARS = 'あいうえおかきくけこさしすせそたちつてとなにぬねのはひふへほまみむめもやゆよらりるれろわをん'
N_IMAGES_PER_CHAR = 200
def __init__(self, dataroot, transform=None):
super(HiraganaDataset, self).__init__()
self.dataroot = dataroot
self.transform = transform
self.n_classes = len(self.CHARS)
# 各ひらがなの画像が入っているフォルダを列挙
char2num = {c: i for i, c in enumerate(self.CHARS)}
folders = [f'U{ord(c):04X}' for c in self.CHARS]
folders = [os.path.join(self.dataroot, d) for d in folders]
# 各フォルダに含まれる画像ファイルを列挙、配列に格納
self.data = []
for d in folders:
char = os.path.basename(d).replace('U', '0x')
char = chr(int(char, 16))
num = char2num[char]
image_files = [os.path.join(d, f) for f in os.listdir(d)]
image_files = [f for f in image_files if f.endswith('.png')]
if len(image_files) > self.N_IMAGES_PER_CHAR:
image_files = np.random.choice(image_files, self.N_IMAGES_PER_CHAR, replace=False)
image_files = sorted(image_files)
self.data.extend([(f, num) for f in image_files])
def __len__(self):
"""ファイルの総数を返す"""
return len(self.data)
def __getitem__(self, idx):
"""データ1つをサンプルする"""
image_file, num = self.data[idx]
image = Image.open(image_file)
if image is None:
raise IOError('Failed to load image: {:s}'.format(f))
if self.transform is not None:
image = transform(image)
return image, num
さて、上記のデータセット・クラスにはコンストラクタの引数にtransformという変数が渡されている。PyTorchではTorchVisionのtransformsモジュールに用意されたデータ操作のためのクラスを用いることで、簡単にデータの前処理を行うことができる。
なお、PyTorch 2.0以降はtransforms.v2という新しいモジュールが導入されており、従来のtransformsよりも幅広いタスクを前処理に追加することができる (参考)。本項でもv2を使用して前処理を行なっていく。
transformsを用いると、例えば、特徴量の抽出で行っていたような
画像をグレースケールに変更
画像をランダムに回転、拡大・縮小
といった操作は v2.GrayScaleやv2.RandomAffineによって実現することができる。複数の前処理操作を組み合わせる場合には、v2.Composeに前処理を行うクラス・インスタンスの配列を渡せば良い。
PyTorchの学習には、torch.Tensor型かつfloat32型の変数を用いるので、上記の二つの前処理と合わせて、型の変換を行うv2.ToImage (torch.Tensor型への変更)とv2.ToDtype (データ内部の数値型を指定された型に変更する)をv2.Composeに与えている。
# TorchVision
from torchvision.transforms import v2
transform = v2.Compose(
[
v2.Grayscale(), # 画像のグレースケール化
v2.RandomAffine(degrees=[-60, 60], scale=[0.8, 1.1]), # ランダム回転、拡大・縮小
v2.ToImage(), # torch.Tensorに型変換
v2.ToDtype(torch.float32, scale=True), # データ型を32bit浮動小数に変換
]
)
transformの準備ができたら、これを前処理計算として、データセット・クラスをインスタンス化する。
dataset = HiraganaDataset(dataroot='hiragana73', transform=transform)
n_classes = dataset.n_classes
print(f'{len(dataset):d} images from {n_classes:d} classes')
9200 images from 46 classes
このようにして作られたデータセットクラスはscikit-learnの時と同様に torch.utils.data.random_split関数を使うことで、訓練用とテスト用にデータを分割することができる。
train_data, test_data = torch.utils.data.random_split(dataset, lengths=[0.8, 0.2])
print(f'#train: {len(train_data):d}, #test: {len(test_data):d}')
#train: 7360, #test: 1840
データセットの分割が完了したら、最後にtorch.utils.data.DataLoaderのインスタンス化を行う。このクラスはデータに対するイテレータとして用いることができ、予めbatch_size=...で指定した数のデータを含むミニバッチを順に取り出してくれる。この際、データの順序をランダムにシャッフルするかどうかはshuffle=...で制御できる。訓練データはシャッフルを行い、テストデータはシャッフルを行わないで用いることが多い。
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=False)
10.4.2. ネットワークの構築#
学習可能なニューラルネットワークはnn.Moduleクラスを継承することで作成できる。まずは、単純な実装として、ひらがなの画像 (48×48画素)を2304次元ベクトルとして扱う場合について見てみる。
今回は、ひらがなの種類が73次元であるので、ネットワークが出力するべきものは73次元のベクトルで、それぞれの要素が、画像がどのひらがならしいかを表わす確率であるようなものである。
このようなベクトルからベクトルへの変換をいわゆる全結合層の連結によって表わすようなネットワークを特にマルチレイヤ・パーセプトロン(multilayer perceptron)やMLPと呼ぶ。
全結合層#
全結合層 (fully-connected layer)は、入力のベクトル\(\mathbf{x} \in \mathbb{R}^n\)に対して、重み行列 \(\mathbf{W} \in \mathbb{R}^{m \times n}\)とバイアスベクトル \(\mathbf{b} \in \mathbb{R}^m\)を使って
のように\(\mathbf{y} \in \mathbb{R}^m\)に変換する操作を表わす。従って、全結合層における学習可能なパラメータは\(\mathbf{W}\)と\(\mathbf{b}\)ということになる。
この全結合層が行う操作は(10.2)から分かるように線形の演算である。
現在の深層学習においては、以下に示す畳み込みニューラルネットで用いられる畳み込み層など、学習可能なパラメータを含む操作は多くの場合、線形の演算によって定義されることがほとんどである。
活性化関数#
しかし、線形の操作を入力のベクトルに対して何回繰り返したところで、それは所詮線形の操作に他ならない。通常の機械学習において扱う入出力の関係は線形なものばかりではないので、深層学習以前にはカーネル法などを用いて非線形な関係を学習するなどの工夫を取り入れていた。
深層学習においては、学習可能なパラメータを含む演算を線形演算で表わす代わりに非線形の活性化関数を用いて、ニューラルネットが表わす入出力データの関係に非線形性を持たせる。
現在の深層学習において、最も広く用いられている活性化関数はReLU (rectified linear unit)と呼ばれるものである。この関数は入力の正の部分だけを残すような関数で、式としては
のように書ける。
以前は、このような活性化関数として、ソフトな閾値関数であるシグモイド関数が使われていた。シグモイド関数\(\sigma(x)\)は
のような関数であり、以下のようなグラフを取る。
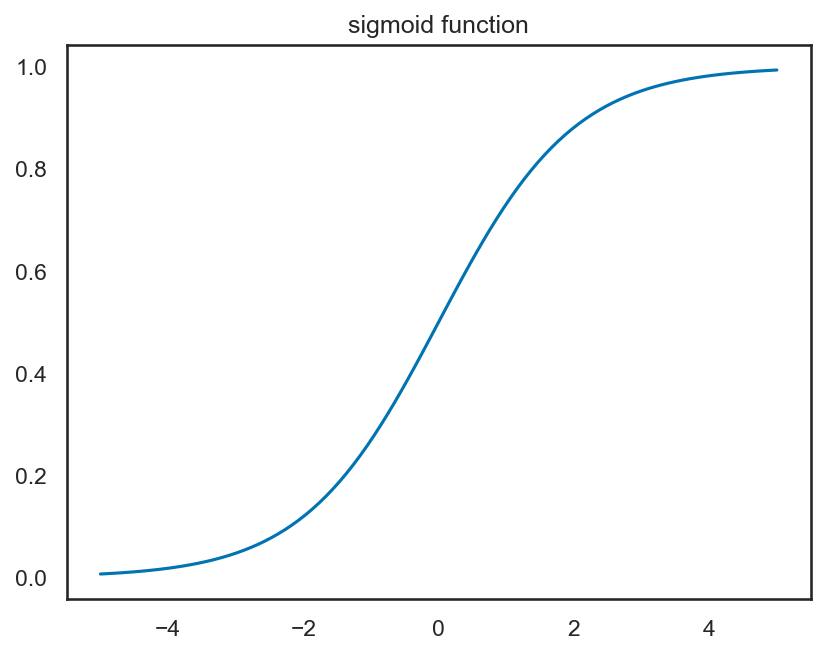
このように、シグモイド関数は入力が0以上の時に1に近い値を、入力が0以下の時に0に近い値を返すようなものであり、これが人間のニューロン同士の結びつきをうまく表わしていると考えられていた。
しかし、実際にニューラルネットの学習を数値計算によって実現しようとする場合、シグモイド関数による活性化は勾配消失の問題を引き起こすことが分かった。
勾配消失とは、連鎖律によって、入力の値に関する出力の勾配を求めていく過程で、小さな値が何度もかけ算され、数値誤差により勾配が0になってしまう現象である。シグモイド関数の微分は、
なのだが、これは、元のシグモイド関数を用いて、
のように書き直せる。シグモイド関数の性質から\(x\)が正負どちらかの方向に大きな値をとれば、1あるいは0に近づいていくため、シグモイド関数の微分\(\sigma'(x)\)は、入力の\(x\)が0から外れた値を取ると、急激に小さくなることが分かる。
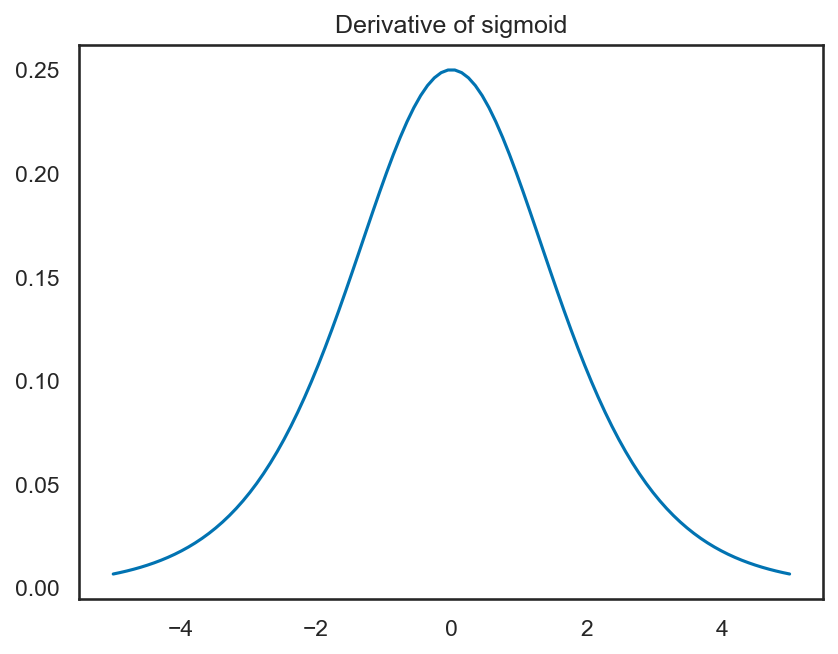
この勾配消失により、ニューラルネットの入力に近い側の層において学習が上手く進まないことが長く問題とされてきたが、ReLUは、その導関数が0か1なので、シグモイド関数で問題となっていたような勾配消失の問題が起きづらくなっている。
このような理由から、現在の深層学習においてはReLUおよび、その変形を活性化関数として用いることが多いのである。
データ正規化#
現在の深層学習においては、バッチ正規化 (batch normalization)を始めとしたデータ正規化をネットワーク上に配置することが多い。これは、スケールの異なるデータに対して、ニューラルネットがパラメータを統一的に学習するのに役立つ。
例えば、バッチ正規化の場合、ミニバッチに含まれるデータに対して計算されている特徴の平均と分散をミニバッチ内で計算し、データの平均が0、標準偏差が1となるように正規化を行う。
この効果はバイアスベクトルを例に取ると分かりやすい。もしデータ正規化を行わない場合、ニューラルネットは輝度がとある画像と輝度が一様に持ち上がった画像を区別するために、異なるバイアスベクトルを学習しなければならない。
しかし、データ正規化によってデータの平均値が0になるように正規化されていれば、一様に輝度が持ち上がるなどの変化を学習パラメータの違いによって判別する必要がなくなるため、よりニューラルネットの学習が効率的に進むようになる。
ただし、このようなデータ正規化は正規化を行うデータ群 (バッチ正規化であればミニバッチ)が、元のデータセットに含まれるデータの分布を上手く近似できていることを仮定しているので、ミニバッチのサイズが小さく、データ分布の近似的精度が悪い場合には、学習が逆に上手く進まないこともあるので注意すること。
なお、PyTorchを始めとする深層学習用のライブラリにおいて、データ正規化のモジュール(nn.BatchNorm1dやnn.InstanceNorm1dなど)は単なるバッチ内でのデータの正規化に加えて、さらに平均と標準偏差を調整するようなパラメータを学習可能変数として持っている。
単純なマルチレイヤ・パーセプトロン#
では、ここまでの議論を踏まえて、単純なマルチレイヤ・パーセプトロンを実装してみる。PyTorchにおいては、学習可能パラメータを含むモジュールはコンストラクタで定義しておく必要があるため、以下のコードでは、全結合層を表わすnn.Linearと、バッチ正規化を表わすnn.BatchNorm1dをコンストラクタの中でインスタンス化しておく。
今回、活性化関数として用いるReLUは学習可能パラメータを持たないので、こちらは、特にコンストラクタでは用意せずに、実際のネットワークが表わす関数の評価処理に対応するforward関数の中でtorch.reluを呼び出す。
理由については後述するが、最終の全結合層に対する活性化関数には単なるソフトマックス関数ではなく、対数ソフトマックス関数を取る方が良い。
class Network(nn.Module):
"""
シンプルなマルチレイヤ・パーセプトロン
"""
def __init__(self, in_features, out_features):
super(Network, self).__init__()
self.fc1 = nn.Linear(in_features, 64)
self.bn1 = nn.BatchNorm1d(64)
self.fc2 = nn.Linear(64, 32)
self.bn2 = nn.BatchNorm1d(32)
self.fc3 = nn.Linear(32, out_features)
def forward(self, x):
x = self.bn1(self.fc1(x))
x = torch.relu(x)
x = self.bn2(self.fc2(x))
x = torch.relu(x)
x = self.fc3(x)
y = F.log_softmax(x, dim=1)
return y
また、PyTorchにはnn.Moduleのサブクラスであるnn.Sequentialがあり、ニューラルネットを構成するモジュールを引数として与えることで、それを順に実行させることもできる。すると、上記の実装はもう少しすっきりと以下のように書ける。
class Network(nn.Sequential):
"""
nn.Sequentialを継承した例
"""
def __init__(self, in_features, out_features):
super(Network, self).__init__(
nn.Linear(in_features, 64),
nn.BatchNorm1d(64),
nn.ReLU(inplace=True),
nn.Linear(64, 32),
nn.BatchNorm1d(32),
nn.ReLU(inplace=True),
nn.Linear(32, out_features),
nn.LogSoftmax(dim=1),
)
このようにして実装したニューラルネットは入出力の次元数を与えて、以下のようにインスタンス化しておく。
model = Network(48 * 48, n_classes)
このようにしてモデルを作成したら訓練時にはmodel.train()を、評価時にはmodel.eval()を予め呼び出しておく (後述のソースコードを参照)。
train()やeval()を呼び出すと、バッチ正規化や後述するドロップアウトの挙動が変化するため、必ずしも訓練時と同じデータでも同じ精度が出ない可能性があることに留意したい。
10.4.3. オプティマイザの準備#
やや天下り式ではあるが、今回は、多くの問題に対して、それなりに良い性能を発揮するAdamをオプティマイザに用いる。ニューラルネットの学習可能パラメータはparameters関数で得られるので、これをオプティマイザの第一引数に指定する。
optim = torch.optim.Adam(model.parameters(), lr=1.0e-4)
10.4.4. 損失関数の設定#
損失関数 (loss function)は、ニューラルネットを訓練するための基準を決める関数であり、問題の種類ごとに、おおよそどのような関数を使えば良いかが決まっている。
識別問題の場合には、2クラス分類なら二値交差エントロピー (binary cross entropy)を、多クラス分類なら交差エントロピー(cross entropy)を用いるのが一般的である。これらを\(\mathcal{L}_{\rm BCE}\), \(\mathcal{L}_{\rm CE}\)と書くことにすると、それぞれ以下の式で表わされる。
なお、\(y \in \lbrace 0, 1\rbrace\), \(x \in [0, 1]\)はそれぞれ正解のラベルと、予測のラベルを表わす。
交差エントロピーには、回帰問題で一般的に用いられる最小二乗誤差などと比べて、ラベルが正解から外れている時に、大きなペナルティが与えられる、という特徴があるため、より分類問題に向いた誤差指標と言える。
Softmax関数の計算#
さて、ここで一つ重要な問題がある。多クラス分類の場合、予測ラベルは、その値が0から1の範囲に収まるようにソフトマックス関数によって活性化されることが一般的である。活性化前の特徴ベクトルを\(\mathbf{x}\)とすると、活性化後のラベル\(\mathbf{y}\)の各次元\(y_d\)は、以下の式で与えられる。
この式を見て分かる通り、ソフトマックス関数は分母と分子に指数関数を含むため、\(\mathbf{x}\)のようそが少し大きな値を取るだけで、ニューラルネットワークの学習に一般的に用いられる単精度浮動小数で表せる範囲を超えてしまう。
そのため、実際のソフトマックス関数の計算においては、予め分母と分子を\(\mathbf{x}\)のうち最大の要素を\(\max_j x_j\)として、\(e^{\max_j x_j}\)で割り算をしておく、ということをする。
より具体的には、以下の式によりソフトマックス関数を計算する。
この違いを実際に計算して確かめてみよう。
# 0-100の間の乱数
np.random.seed(3)
x = torch.tensor(np.random.uniform(0, 100, size=(10)), dtype=torch.float32)
# 単純な計算
softmax0 = torch.exp(x) / torch.exp(x).sum()
# 工夫した計算
max_x = torch.max(x)
softmax1 = torch.exp(x - max_x) / torch.exp(x - max_x).sum()
# 結果の表示
print(' Input:', x)
print('Simple:', softmax0)
print('Better:', softmax1)
Input: tensor([55.0798, 70.8148, 29.0905, 51.0828, 89.2947, 89.6293, 12.5585, 20.7243,
5.1467, 44.0810])
Simple: tensor([0., 0., 0., 0., nan, nan, 0., 0., 0., 0.])
Better: tensor([5.7665e-16, 3.9313e-09, 2.9778e-27, 1.0593e-17, 4.1712e-01, 5.8288e-01,
1.9686e-34, 6.9264e-31, 1.1892e-37, 9.6426e-21])
いかがだろうか。このように、単純にソフトマックス関数を計算してしまうと、入力の\(\mathbf{x}\)に一つ、大きな値が含まれるだけで、計算に失敗してしまうことが分かる。自分でソフトマックス関数を書く場合には注意されたい (特にNumPyには標準のソフトマックス関数が実装されていない)。
SoftmaxとLogSoftmax#
さて、続いてはソフトマックス関数(softmax)と、対数ソフトマックス関数(log-softmax)の違いについて見ていきたい。前述のニューラルネットワークでは、最終層の活性化関数に対してソフトマックス関数ではなく対数ソフトマックス関数を用いていたが、もちろんこれにも意味がある。
例えば、次の例を見てみてほしい。
np.random.seed(3)
x = torch.tensor(np.random.uniform(-100, 100, size=(10)), dtype=torch.float32)
softmax = F.softmax(x, dim=0)
print('Softmax:', softmax)
Softmax: tensor([6.4727e-31, 3.0083e-17, 0.0000e+00, 2.1843e-34, 3.3867e-01, 6.6133e-01,
0.0000e+00, 0.0000e+00, 0.0000e+00, 1.8099e-40])
この例では、ソフトマックス関数の出力で、単精度浮動小数では表せないような微小な値が出てきてしまい、アンダーフローが起こって、一部の値が0になっていることが分かる。このような出力に対して対数を取ってしまえば、\(-\infty\)のような好ましくない値が得られてしまう。
これは、交差エントロピー誤差の計算に影響を与える。前述の通り、交差エントロピーの計算には対数が含まれるので、\(-\infty\)のような不正な値が入ってくると、誤差関数の計算に失敗してしまうのである。そこで、より数値計算的に安定なやり方で、ソフトマックス関数の対数、即ち対数ソフトマックス関数を求めてしまおう、というのが、最終出力層を対数ソフトマックス関数で活性化している理由である。
ソフトマックス関数に対して対数を取ると、以下のような式になる。
この式において、\(x_d\)に大きさのばらつきがあると、\(e^{x_d}\)の値はさらに大小差が大きくなり、数値計算においては、その和を取ったときに桁落ち誤差が起こって、相対的に小さな値が無視されてしまう。
# 桁落ち誤差の例
a = np.array([0.00001], dtype='float32')
b = np.array([10000.0], dtype='float32')
print(a + b)
[10000.]
このような桁落ち誤差を防ぐために、ある数列の「指数の和」の「対数」を計算するときには、一工夫必要になる。具体的には、先ほどのソフトマックス関数の計算の時と同様に、各\(x_d\)から、要素の最大値\(\max_j x_j\)を引き算しておく、ということをする。すなわち、
のように計算を行なう。すると、各\(e^{x_d - \max_j x_j}\)は0から1の間の値を取るため、桁落ち誤差の影響を抑えることができる。このような計算がF.softmaxやnn.Softmaxの中では行なわれており、計算結果を比較すると、以下のように\(-\infty\)のような不正な値を影響を受けることなく計算が行なわれていることが分かる。
logsoftmax0 = torch.log(F.softmax(x, dim=0))
logsoftmax1 = F.log_softmax(x, dim=0)
print('Simple:', logsoftmax0)
print('Better:', logsoftmax1)
Simple: tensor([-69.5126, -38.0426, -inf, -77.5066, -1.0827, -0.4135, -inf,
-inf, -inf, -91.5102])
Better: tensor([ -69.5126, -38.0426, -121.4912, -77.5066, -1.0827, -0.4135,
-154.5551, -138.2235, -169.3787, -91.5102])
さて、対数ソフトマックス関数の出力を\(z\)とすれば、交差エントロピーは
のように書き直せる。この関数こそが非負対数尤度誤差 (non-negative log-likelihood)であり、PyTorchではnn.NNLLossとして用意されている。
以上の議論から、より高精度な識別結果を得るためには、
最終層を対数ソフトマックス関数 (
nn.LogSoftmaxorF.log_softmax)で活性化する損失関数に非負対数尤度誤差 (
NNLLoss)を用いる
という工夫を行なうのが良い。
PyTorchにおいては、慣習的にcriterionという変数に損失関数を取ることが多く、それに倣って、以下のようにNNLLossクラスをインスタンス化しておく。
# 損失関数の準備
criterion = nn.NLLLoss()
NLLLossとCrossEntropyLoss
前述の説明では、単純なソフトマックス関数を分類問題の活性化関数として利用することの危険性を示すために、あえて対数ソフトマックス関数を明示的に使用する方法について述べた。
ただし、PyTorchの多クラス分類用の損失関数クラスであるCrossEntropyLossは、活性化されていない最終出力と、クラスインデックスの集合を引数として与えると、内部で対数ソフトマックスの適用とNLLLoss同様の損失関数の計算を行なってくれる。
従って、ソフトマックス関数の問題と各損失関数の仕組みを正しく理解しているならCrossEntropyLossを使っても良い。
10.4.5. トレーニング・ループ#
さて、ここまで準備ができたら、最後にニューラルネットワークを訓練するための繰り返し計算をforループによって実装しよう。
深層学習においては、トレーニングデータを何周分トレーニングするかをエポックという用語で表わす。以下の例では5周分、すなわち5エポックの学習を行なっている。
学習と同時に、進行状況が分かるようにしておくことはとても大事で、以下の例ではtqdmモジュールを用いて、訓練の進み具合と、その時の損失関数の値、ならびに識別精度を表示するようにしている。
# モデルの初期化
model = Network(48 * 48, n_classes)
# オプティマイザの初期化
optim = torch.optim.Adam(model.parameters(), lr=1.0e-3)
# トレーニング・ループ
losses = []
accuracies = []
model.train()
for epoch in range(epochs):
# 進行状況の可視化
pbar = tqdm(train_loader)
for data in pbar:
# 訓練データの取り出し
X, y_true = data
X = X.reshape((X.size(0), -1))
# 推定と損失関数の評価
y_pred = model(X)
loss = criterion(y_pred, y_true)
acc = (torch.argmax(y_pred, dim=1) == y_true).float().mean()
losses.append(loss.item())
accuracies.append(acc.item())
pbar.set_description(f'[MLP] epoch={epoch + 1:d}, loss={loss.item():1.3f}, acc={acc.item():1.3f}')
# 誤差逆伝搬によるパラメータの更新
optim.zero_grad()
loss.backward()
optim.step()
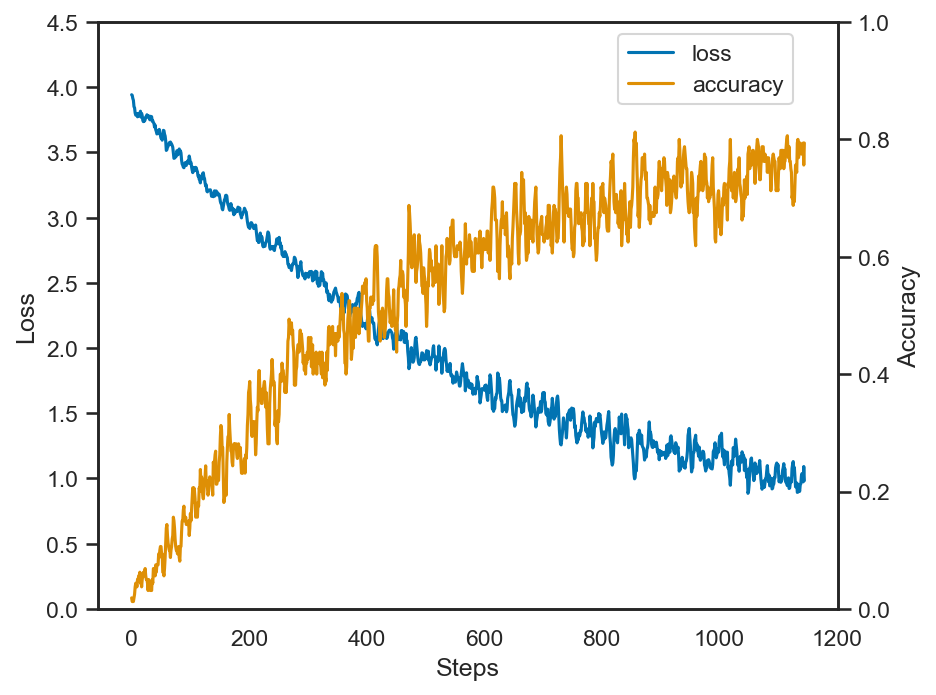
上記の学習について、誤差と精度の変化をプロットしてみる。そのままだと、上下の振動が大きく見づらいので、移動平均を取って曲線を滑らかにしておく。
# 移動平均を取る (= ボックス・フィルタをかける)
box_size = 5
box = np.ones((box_size)) / box_size
losses = np.convolve(losses, box, mode='valid')
accuracies = np.convolve(accuracies, box, mode='valid')
pbar = tqdm(test_loader)
n_succ = 0
for data in pbar:
X, y_true = data
X = X.reshape((X.size(0), -1))
model.eval()
with torch.no_grad():
y_pred = model(X)
n_succ += (torch.argmax(y_pred, dim=1) == y_true).float().sum()
total_acc = n_succ / len(test_data)
print(f'Acc: {total_acc:.3f}')
Acc: 0.707
このように、PyTorchを使ってニューラルネットワークを構築することで、一定の識別精度を得ることができた。
しなしながら、MLPにおいては画像を単純なベクトルとして扱うため、画像の空間的な情報を活かすことが出来ず、その結果はFisherベクトルを用いた場合の精度等には及ばない。
10.5. 畳み込みニューラルネットによる学習#
ここまでは、全結合層からなるマルチレイヤ・パーセプトロンによる学習を見てきたが、今回は取り扱う対象が画像であるため、畳み込みニューラルネットにより、より効果的な学習が期待できる。
全結合層は、入力のベクトルに対して、行列を作用させて、さらにその結果にバイアスベクトルを加算する、というものであった。この操作は、畳み込みニューラルネットで用いられる畳み込み層においてもほとんど同じである。
今、入力が画像であり、それが画素ごとに特徴化されて\((H, W, D)\)という大きさを持つデータであるとしよう。なお、\(H\)は画像 (特徴マップ)の高さ、\(W\)は幅、\(D\)は各画素が持つ特徴の次元である。
このデータを畳み込み層によって\((W', H', D')\)に変換することを考える。畳み込み層が学習可能な重みが畳み込みカーネルを表わす二次元のマップであり、これが\(D \times D'\)個用意される。カーネルのサイズを\(K\times K\)とする場合、畳み込み前後の特徴マップのサイズには、
という関係がある。また、畳み込み層は、カーネルの大きさに加えて、何画素飛ばしでカーネルを適用するかを表わすストライド\(S\)と、画像の周りを何らかの値で埋めて、大きさを調整するパディング\(P\)をパラメータとして持つ。これらの値を加味すると、畳み込み前後の画像サイズの関係は、以下のように書き直せる。
現在は、ニューラルネットワークの畳み込み層で、画像や特徴マップのサイズを変更することは少なく、多くの場合、\(P=(K-1)/2\), \(S=1\)とすることで、畳み込み前後のサイズが変わらないようにすることが多い。例えば、\(3\times 3\)の畳み込みを用いる場合、\(P=1\), \(S=1\)と設定する。
その代わり、画像や特徴マップのサイズを変更する操作としてプーリングという操作を行なう。プーリングは、\(2 \times 2\)などの小さな画像領域において、その画素が持つ特徴の最大値や平均を取るような操作を指す。PyTorchにおいては、最大を取る操作がnn.MaxPool2dおよびF.max_pool2dに、平均を取る操作がnn.AvgPool2dおよびF.avg_pool2dに用意されている。
これらを用いて簡単な畳み込みニューラルネットを実装したものが以下である。
class CNN(nn.Module):
"""
畳み込みニューラルネット
"""
def __init__(self, in_channels, out_channels):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels, 64, 3, 1, 1)
self.bn1 = nn.BatchNorm2d(64)
self.conv2 = nn.Conv2d(64, 32, 3, 1, 1)
self.bn2 = nn.BatchNorm2d(32)
self.conv3 = nn.Conv2d(32, 16, 3, 1, 1)
self.bn3 = nn.BatchNorm2d(16)
self.fc3 = nn.Linear(6 * 6 * 16, out_channels)
def forward(self, x):
x = torch.relu(self.bn1(self.conv1(x))) # (B, 48, 48 64)
x = F.max_pool2d(x, 2) # (B, 24, 24, 64)
x = torch.relu(self.bn2(self.conv2(x))) # (B, 24, 24, 32)
x = F.max_pool2d(x, 2) # (B, 12, 12, 32)
x = torch.relu(self.bn3(self.conv3(x))) # (B, 12, 12, 16)
x = F.max_pool2d(x, 2) # (B, 6, 6, 16)
x = x.reshape((x.size(0), -1)) # (B, 6 * 6 * 16)
x = self.fc3(x) # (B, out_channels)
y = F.log_softmax(x, dim=1)
return y
ところで、これまで、学習はCPUを用いて計算してきたが、上記の畳み込みニューラルネットになってくると、CPUだけの計算では少々時間がかかるようになってくる。
そこで、GPUが使える環境ではGPUを使うようにデバイスの設定を行なう。GPU上ではNVIDIA社のCUDA (compute unified device architecture)を用いて計算が行なわれ、GPUの性能にもよるが、CPUより遙かに高速な学習が可能である。
CUDAが使えるかどうかの判定にはtorch.cuda.is_available()関数を用いる。
# デバイスの判定
if torch.cuda.is_available():
device = torch.device('cuda')
else:
device = torch.device('cpu')
print('Your device is', device)
Your device is cpu
デバイスが取得できたら、ネットワークならびに学習データを、デバイスに転送する操作が必要になる。具体的には、それぞれに用意されたto(...)という関数に対して、上記のdeviceインスタンスを指定する。
# ネットワークおよびオプティマイザのインスタンス化
model = CNN(1, n_classes).to(device)
optim = torch.optim.Adam(model.parameters(), lr=1.0e-3)
losses = []
accuracies = []
model.train()
for epoch in range(epochs):
pbar = tqdm(train_loader)
for data in pbar:
# データのデバイスへの転送
X, y_true = data
X = X.to(device)
y_true = y_true.to(device)
# 推論ならびに損失関数の評価
y_pred = model(X)
loss = criterion(y_pred, y_true)
acc = (torch.argmax(y_pred, dim=1) == y_true).float().mean()
losses.append(loss.item())
accuracies.append(acc.item())
pbar.set_description('[CNN] loss={:1.3f}, acc={:1.3f}'.format(loss.item(), acc.item()))
optim.zero_grad()
loss.backward()
optim.step()
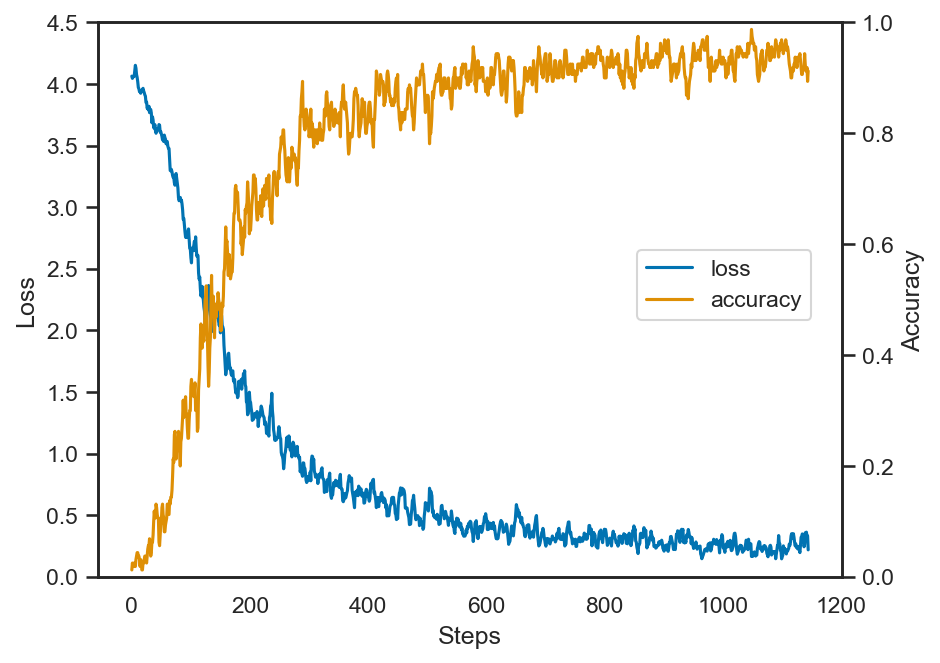
# 移動平均を取る (= ボックス・フィルタをかける)
box_size = 5
box = np.ones((box_size)) / box_size
losses = np.convolve(losses, box, mode='valid')
accuracies = np.convolve(accuracies, box, mode='valid')
pbar = tqdm(test_loader)
n_succ = 0
for data in pbar:
X, y_true = data
X = X.to(device)
y_true = y_true.to(device)
model.eval()
with torch.no_grad():
y_pred = model(X)
n_succ += (torch.argmax(y_pred, dim=1) == y_true).float().sum()
total_acc = n_succ / len(test_data)
print(f'Acc: {total_acc:.3f}')
Acc: 0.901
このようにCNNを用いて画像としての特徴をより意識するようなニューラルネットワークを用いたことで、識別の精度が大幅に向上したことが分かる。
問
MLPとCNNを用いた画像識別の各例について、オプティマイザの種類によって、誤差関数の収束と識別精度の上昇がどのように変化するかを調査せよ。
10.6. 学習結果の保存#
実際に深層学習をアプリケーションで使う際には、予め時間を掛けてニューラルネットワークを学習しておき、その学習結果だけを読み出して、応用に使用する場合がほとんどだろう。また、途中まで学習がされているネットワークを読み出して、そこから別のデータでファイン・チューニングを行なう場合もあるだろう。
そのような時には、ネットワークのパラメータを*.pthファイルに保存しておくことが一般的である。ネットワークやオプティマイザには、state_dict()関数が用意されていて、パラメータとその名前を格納した辞書を取得することができる。このような辞書がネストしたものをtorch.save関数に渡すことで重みを保存することができる。
ckpt = {
'model': model.state_dict(),
'optim': optim.state_dict(),
}
torch.save(ckpt, 'ckpt.pth')
このようにして、保存したパラメータはtorch.load関数で辞書型として読み出すことができ、対応する辞書をload_state_dict関数に指定することでパラメータを上書きすることができる。
# ネットワークとオプティマイザの別インスタンスを作成
model2 = CNN(1, n_classes)
model2.to(device)
optim2 = torch.optim.Adam(model2.parameters(), lr=1.0e-3)
# 学習済みパラメータの読み込み
ckpt2 = torch.load('ckpt.pth')
model2.load_state_dict(ckpt2['model'])
optim2.load_state_dict(ckpt2['optim'])
再度、読み込んだパラメータを用いて性能を確認してみる。
pbar = tqdm(test_loader)
n_succ = 0
for data in pbar:
X, y_true = data
X = X.to(device)
y_true = y_true.to(device)
model2.eval()
with torch.no_grad():
y_pred = model2(X)
n_succ += (torch.argmax(y_pred, dim=1) == y_true).float().sum()
total_acc = n_succ / len(test_data)
print(f'Acc: {total_acc:.3f}')
Acc: 0.897
このように、パラメータの読み込みにより、以前の結果を再現できていることが分かる。
なお、本項の例はHiraganaDatasetの内部で画像を読み込むときに評価時もランダム回転等を適用しているため、実行する度に多少精度が変化する。
異なるデバイスでのパラメータの読み込み
学習を行ったデバイスと異なるデバイスで.pthファイルを読み込む場合、単に torch.loadを呼び出すだけではRuntimeErrorになってしまう。
これを防ぐにはtorch.loadの引数にmap_location=...を指定して、どの種類のデバイスに読み込むのかを指定する。例えばCUDA上で学習を行って得たパラメータをCPU上で読み込む場合には、以下のようにすれば良い。
ckpt = torch.load("ckpt.pth", map_location=torch.device("cpu"))
10.7. 過学習を防ぐための工夫#
上記のCNNによる文字分類の結果を見てみると、訓練時の精度と比較して、テスト時の精度がやや劣っていることが分かる。このような訓練データに対して、過度に高い精度が出てしまう現象を過学習と呼ぶ。
過学習を防ぐための方法にはいくつかあるが、主なものとして以下の4つが挙げられる。
学習可能なパラメータの数を減らす
訓練データ数を増やす
正則化項の追加
ドロップアウトの導入
学習パラメータの数は、過学習の主要な原因の一つで、これはニューラルネットに限らず、モデルが複雑になればなるほど、必要な学習データの数が増す。これは、単純には、連立方程式における制約式の数と未知数の数の関係と同じであり、パラメータ数が多ければ制約を増やす意味で多くの訓練データが必要であり、訓練データの量が十分でないときには、より簡素な機械学習モデルを使う方が過学習の影響を抑えられる。
故に、どのような問題に対しても、無差別に深層学習を適用すれば良い結果が得られるわけではない、という点には最大の注意を払ってほしい。やはり、深層学習が発展した今でも、問題に応じて適切な手法を選ばなければならないことに変わりはない。
また、正則化項の導入により過学習を防ぐことも可能である。正則化項とは、非常に大雑把な議論では、各パラメータの絶対値が大きくなりすぎないようにペナルティ項を追加することに対応する。このようなペナルティ項には様々な種類があるが、よく用いられるのはL1正則化、ならびにL2正則化である。L1正則化は学習可能パラメータの絶対値の和を使い、L2正則化は学習可能パラメータの二乗の和を用いる。
PyTorchを用いる場合、L2正則化であれば、オプティマイザをインスタンス化する際に引数としてweight_decay=...というパラメータを指定することで、正則化がかかる。例えば、
optim = torch.optim.Adam(model.parameters(), lr=1.0e-3, weight_decay=1.0e-6)
といった感じで、この場合には、パラメータの二乗和に対してweight_decay=...で指定した値が乗算されたものが損失関数に追加される。
一方、L1正則化を行ないたい場合には、陽にパラメータの大きさの絶対値の和を足し上げていく必要がある。
# L1正則化の実装例
l1_reg = 0.0
for p in model.parameters():
l1_reg += p.abs().sum()
最後に紹介するDropoutは、全結合層や畳み込み層中のチャネル間の結びつきをランダムに無効化しながら学習するという仕組みである。例えば、全結合層により、ベクトルの次元数を\(D_1\)から\(D_2\)に変える場合、Dropoutされる確率を\(p \in (0, 1)\)として、\(p D_1 D_2\)個の行列要素を訓練時のみランダムに0で埋めてしまう。
こうすることにより、機械学習モデルは、どのパラメータを使った場合にも、まんべんなく訓練データに対する予測ができるように学習が進み、結果として過学習を防ぐことができる。
PyTorchで実装する場合には、活性化関数の後にnn.DropoutあるいはF.dropoutを追加すれば良い。なお、PyTorchのDropoutに指定する確率はパラメータを0で埋める割合である (つまりDropout(p=0.0)とすると、何もしないことと同義になる)。
問
過学習を防ぐための工夫に示した方法によって、どの程度、過学習が抑制できるかを実際に試してみよ。
レイヤーの順序
現在のニューラルネットワークにおいては、
全結合層、畳み込み層などの学習可能な線形操作
バッチ正規化などのデータ正規化
活性化関数
ドロップアウト
のような順序で演算を行なうことが多いが、この善し悪しについてはあまりはっきりとしないところがある。特に、データ正規化と活性化関数の順序については、その演算の意味を考えると、順序が逆の方が良いと思える部分も多い。
データ正規化の後に活性化関数をもってくる、という順序はバッチ正規化の原論文である[Ioffe and Szegedy, 2015]で提唱された順序であり、多くの手法がこの順序を採用している。しかし、データ正規化がデータの平均を0に合わせることを考えると、その後に、負の値を0で埋めてしまうReLUを適用するのは、やや不適切に思えなくもない。
さらに言えば、データ正規化の効果は全結合層などの線形操作においてバイアスベクトルの学習を促進する効果にあるわけだから、線形操作の直前にデータ正規化が行なわれる方が自然である。
実際、「線形操作」→「活性化関数」→「ドロップアウト」→「データ正規化」の順序の方が性能が向上するという見方もある。このように、論文に書かれていることが常に正しいとは限らないので、論文を読むときには、多少は疑いの目をもって読むことが大事である。
10.8. 参考文献#
Kunihiko Fukushima. Neocognitron: a self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biological Cybernetics, 36(4):193–202, apr 1980. doi:10.1007/bf00344251.
Caglar Gulcehre, Marcin Moczulski, and Yoshua Bengio. Adasecant: robust adaptive secant method for stochastic gradient. In IEEE International Joint Conference on Neural Network. 2014.
J J Hopfield. Neural networks and physical systems with emergent collective computational abilities. Proceedings of the National Academy of Sciences, 79(8):2554–2558, April 1982. doi:10.1073/pnas.79.8.2554.
Sergey Ioffe and Christian Szegedy. Batch normalization: accelerating deep network training by reducing internal covariate shift. In International conference on machine learning, 448–456. pmlr, 2015.
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. Imagenet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, 1097–1105. 2012. doi:10.1145/3065386.
David E. Rumelhart, Geoffrey E. Hinton, and Ronald J. Williams. Learning representations by back-propagating errors. Nature, 323(6088):533–536, October 1986. doi:10.1038/323533a0.