10. 深層生成モデル#
深層学習の登場以前にも、特定のデータやルールから新しい画像を作ろうとする試みはあった。
データセットを用いた画像生成の枠組みでは、人間の顔画像について、完全に目や鼻などの位置が揃った画像群から、主成分分析によって新しい顔画像を作るEigenface [40]や、大量の画像群の中に現れる類似シーンの画像を用いて画像補完を行う技術 [41]などが提案されてきた。
しかし、現在のように一般的な自然画像を学習して、そこから新しい画像を生成するような技術は実現できていなかった。本節では、深層学習の登場以降に現れた深層生成モデルの中で、特に変分オートエンコーダ (VAE) と敵対的生成ネットワーク (GAN)を中心に紹介する。
参考資料
『ディジタル画像処理 改訂第二版』 P.293 第13章 深層学習による画像認識と生成
『生成Deep Learning』 著: David Foster, 訳: 松田 晃, 小沼 千絵
クイズ
現在の生成AIは、人間にとって非常に自然な画像を作成することができる。では、人間が見て自然といえる画像を作るには、どのくらいの訓練データが必要になるだろうか?
人間にとって自然、ということを人間が一生のうちに少なくとも一度目にする、ということだと言い換えた時、どのくらいの画像量が必要かを見積もってみよう。

10.1. 確率的画像生成モデル#
個別の手法について説明する前に「画像を生成する」という行為を少し数学的に表してみよう。
深層学習を用いて画像を生成する場合には、通常、大量の画像を訓練データとして用いる。話を単純化するために、画像が一定の大きさ (例えば64✕64ピクセル)のカラー画像として表されているとすると、画像をベクトルとみなすことができる。以後、画像を表すベクトルを \(\mathbf{x}\) と表すことにする。
すると、訓練データ \(\mathcal{D} = \{ \mathbf{x}_1, \ldots, \mathbf{x}_N \}\) というのは、画像データの背後にある未知の確率分布 \(p_\text{data}(\mathbf{x})\) からサンプルされた値であり、理想的には、各 \(i\) について独立に、
のように書けると考える。
生成モデルの目的は、未知の画像データの分布である \(p_\text{data}(\mathbf{x})\) を直接求めることではなく、訓練データ \(\mathcal{D}\) を用いて\(p_\text{data}(\mathbf{x})\) を近似する確率分布を求めることである。
具体的には、ニューラルネットを含む生成モデルのパラメータを \(\theta\) とし、関数 \(p_\theta(\mathbf{x})\) によって \(p_\text{data}(\mathbf{x})\) を近似する。ニューラルネットの訓練は、訓練データに対してパラメータ \(\theta\) を最適化する問題であり、次の対数尤度の最大化問題に帰着される。
すなわち、生成モデルのパラメータ \(\theta\) は、関数 \(p_\theta(\mathbf{x})\) が、訓練データ \(\mathcal{D}\) に対して、できるだけ高い確率を与えるように最適化される。
しかし、画像の空間は非常に高次元であるため、\(p_\theta(\mathbf{x})\) を直接モデル化したり、そこから新しい画像をサンプリングしたりすることは一般に困難である。
そこで、多くの生成モデルでは \(p_\theta(\mathbf{x})\) を直接モデル化するのではなく、\(\mathbf{x}\) とは別の確率変数 \(\mathbf{z}\) を導入し、\(\mathbf{z}\) から \(\mathbf{x}\) への写像をニューラルネットを用いて表す。この時、 \(\mathbf{z}\) を 潜在変数 (latent variable)と呼び、 \(\mathbf{z}\) が属する空間を 潜在空間 (latent space)と呼ぶ。通常、潜在変数 \(\mathbf{z}\) は、多変量正規分布のような単純な分布に従うと仮定される。
ここで、確率分布 \(p_\theta(\mathbf{x})\) を、潜在変数 \(\mathbf{z}\) に対して周辺化すると次の式が得られる。
従って、対数尤度の期待値は次のように書ける。
ただし、この式では潜在変数 \(\mathbf{z}\) に関する積分の計算が対数の内側に現れる。潜在変数 \(\mathbf{z}\) が単純な分布に従うとしても、この積分を解析的・数値的に計算することは困難である。故に、その値の対数をとって、さらにその値の \(\mathbf{x}\) に関する期待値を計算することもできない。
また、訓練データがあるとはいっても、適当にサンプルされた潜在変数 \(\mathbf{z}\) が、訓練データ中のどの画像に対応するかが事前に分かっているわけではない。
このような理由から、既存の生成モデルの多くは、潜在変数 \(\mathbf{z}\) を個々の画像と1対1に対応させる代わりに \(\mathbf{z}\) から生成される画像 \(\mathbf{x}\) の分布が訓練データの分布に近づくようにニューラルネットを訓練する。
ここで、潜在変数 \(\mathbf{z}\) は正規分布のような単純な分布に従うと仮定したので、このようにニューラルネットを訓練しておけば、
\(\mathbf{z}\) を単純な分布からサンプルする
\(\mathbf{z}\) をニューラルネットに入力して \(\mathbf{x}\) に変換する
という手順により、画像を生成することができるようになる。
以後で紹介する深層生成モデルは、いずれも「何らかの乱数から複雑な画像分布を作る」という考え方を共有している。ただし、尤度をどのように扱うか、また画像をどのようにサンプルするかはモデルごとに異なる。
VAEは変分下限を用いて尤度を近似的に扱い、GANは判別器を用いて生成分布をデータ分布に近づける。また、拡散モデルはノイズを少しずつ取り除く過程として画像生成を定式化する。
まとめ: 確率的画像生成モデル
確率的な画像生成は、訓練データ中の画像の分布を事前分布をモデル化することで実現される
深層学習を用いる場合は、潜在変数 \(\mathbf{z}\) をニューラルネットに入力して、画像 \(\mathbf{x}\) を生成する
ニューラルネットが潜在変数をどのように画像に写すか、また訓練データからどのように尤度関数を推定するかはモデルごとに異なる
10.2. 変分オートエンコーダ (VAE)#
変分オートエンコーダ (Variational Autoencoder, VAE)は、自己符号化器 (autoencoder)の拡張で画像を生成するためのニューラルネットである [42]。
通常の自己符号化器と同様にVAEはエンコーダとデコーダから構成される。通常の自己符号化器では、エンコーダは画像 \(\mathbf{x}\) を潜在変数 \(\mathbf{z}\) に写し、デコーダは潜在変数 \(\mathbf{z}\) を画像 \(\mathbf{x}\) に写し、両者は入力した画像を再構成するように学習される。
一方で、VAEは潜在変数の扱いが異なる。VAEのエンコーダは、画像 \(\mathbf{x}\) を入力とし、潜在変数 \(\mathbf{z}\) が従うであろう正規分布の平均と分散を出力するように学習される。一方で、デコーダは通常の自己符号化器と同様に、潜在変数 \(\mathbf{z}\) を入力とし、画像 \(\mathbf{x}\) を出力する (図 10.1)。

図 10.1 変分オートエンコーダ (VAE)の構造#
10.2.1. 変分下限#
VAEを理解するうえで大事な考え方に 変分下限 (Evidence Lower Bound, ELBO) がある。VAEの説明に入る前に、まずはELBOの考え方について説明しよう。
当然ながら、画像生成のためのニューラルネットは画像データセット \(\mathcal{D} = \{ \mathbf{x}_1, \mathbf{x}_2, \ldots, \mathbf{x}_N \}\)を用いて訓練される。ここで、各画像がサンプルされる確率を \(p_\text{data}(\mathbf{x})\) とすると、画像生成は対数尤度の期待値
をニューラルネットのパラメータ \(\theta\) について最大化する問題であると考えられるのであった。前述の通り、この積分を解析的・数値的に計算することは容易ではない。
そこで、変分Bayes (variational Bayes)と呼ばれる手法を用いて、対数尤度 \(\log p_\theta(\mathbf{x})\) の下界を求める。これにより、前述の積分を計算しやすい形に変形する。
変分Bayesでは、 \(p_\theta(\mathbf{z} | \mathbf{x})\) の近似分布として \(q_\phi (\mathbf{z} | \mathbf{x})\) を導入する。 \(q_\phi (\mathbf{z} | \mathbf{x})\) は、パラメータを \(\phi\) とするニューラルネットで、 画像 \(\mathbf{x}\) を入力として、潜在変数 \(\mathbf{z}\) が従うであろう分布を出力する役割を持つ。
この近似分布 \(q_\phi (\mathbf{z} | \mathbf{x})\) を用いると、対数尤度 \(\log p_\theta(\mathbf{x})\) は次のように書き換えられる。
この式には何らかの関数の平均の対数を取る、という操作が含まれている。ここでJensenの不等式と呼ばれる次の不等式を用いる。
Jensenの不等式
とある確率変数 \(X\) と下に凸の関数 \(f\) について、次の不等式をJensenの不等式と呼ぶ。
逆に \(f\) が上に凸の関数であるときは次式が成り立つ。
対数関数は上に凸の関数であるため、Jensenの不等式を用いると、(10.1)は次のように書き直せる。
ただし、式中の \(D_\text{KL}(q_\phi(\mathbf{z} | \mathbf{x}) || p(\mathbf{z}))\) は、Kullback-Leiblerダイバージェンスと呼ばれる、2つの確率分布の差を表す指標で、
のように定義される。
(10.2) の右辺が、ELBOであり、ELBOが周辺対数尤度の下界を与えていることが分かる。
10.2.2. VAEの訓練#
VAEの訓練では、周辺対数尤度を最大化する代わりにELBOを最大化することで、ニューラルネットのパラメータ \(\theta\) と \(\phi\) を最適化する。
VAEは自己符号化器 (autoencoder)の一種であるので、ニューラルネットはエンコーダとデコーダによって構成される。2つの確率分布 \(p_\theta(\mathbf{x} | \mathbf{z})\) と \(q_\phi(\mathbf{z} | \mathbf{x})\) はそれぞれ、エンコーダとデコーダの処理に対応している。
ここで、エンコーダは入力の画像 \(\mathbf{x}\) を受け取り、潜在変数 \(\mathbf{z}\) を出力するようなニューラルネットであって、 \(q_\phi(\mathbf{z} | \mathbf{x})\) からのサンプリングを担う。一方、デコーダは潜在変数 \(\mathbf{z}\) を受け取り、画像 \(\mathbf{x}\) を出力するようなニューラルネットであって、 \(p_\theta(\mathbf{x} | \mathbf{z})\) からのサンプリングを担う。
VAEを訓練するための損失関数は、負のELBOを最小化する形で、次のように定義される。
さて、\(\mathbf{z}\) が多変量正規分布 (もしくは他の解析的にサンプリング可能な分布)に従うと仮定したことを思い出してほしい。この条件を満たすために、エンコーダは直接 \(\mathbf{z}\) を出力する代わりに、多変量正規分布の平均 \(\boldsymbol{\mu}\) と分散 \(\boldsymbol{\sigma}^2\) を出力するように設計される。
(10.3) の第一項は、エンコーダに渡された画像 \(\mathbf{x}\) とデコーダからの出力 \(\mathbf{x}'\) の間の誤差を用いて表される。VAEの原論文 [42] では、画像 \(\mathbf{x}\) がモノクロ画像で、各画素が独立にベルヌーイ分布に従うと仮定して、交差エントロピー誤差を用いていた。画像の各画素が連続値を取る場合には、平均二乗誤差を用いられることが多い。
一方で、 (10.3) の第二項はエンコーダが出力する平均 \(\boldsymbol{\mu}\) と分散 \(\boldsymbol{\sigma}\) を持つ正規分布と \(p(\mathbf{z})\)として仮定した標準正規分布との間のKLダイバージェンスによって定義される。
10.2.3. 条件付き画像生成#
VAEを用いると、単に訓練データに従うような画像を生成するだけでなく、一定の条件を満たす画像を生成することもできる。例えば、MNISTのような手書き数字の画像を作る場合に、0の画像だけを作る、8の画像だけを作るといった画像生成が可能である。
条件付きの画像生成が可能なVAEのことを特にConditional VAEから CVAE と呼ぶこともある。
このような画像生成を可能とするためには、画像 \(\mathbf{x}\) の事前分布 \(p_\theta(\mathbf{x})\) の代わりに、条件付きの分布 \(p_\theta(\mathbf{x} | \mathbf{c})\) をモデル化すれば良い。ここで \(\mathbf{c}\) は、生成される画像が満たすべき条件を表す変数である。
ここで、通常のVAEと同様に変分Bayesを用いてELBOを求めると、次のようになる。
この式では、エンコーダとデコーダの両方が、条件 \(\mathbf{c}\) を入力として受け取るように設計されていることが分かる。典型的な実装では、画像の各画素に条件を表すone-hotベクトルを結合してエンコーダに入力する、または潜在変数 \(\mathbf{z}\) と条件 \(\mathbf{c}\) を結合してデコーダに入力する、といった方法が用いられる。
まとめ: VAE
VAEは、自己符号化器の拡張で、潜在変数を確率分布として扱う
VAEの訓練は、ELBOの最大化に対応し、再構成誤差とKLダイバージェンスの和を最小化することに対応する
VAEを用いた条件付き画像生成では、エンコーダとデコーダの両方が条件の情報を入力すれば良い
10.3. 敵対的生成ネットワーク (GAN)#
GANは、画像を生成する生成器 (generator)と、画像がデータセットに含まれる真の画像なのか、生成器によって作られた仮の画像なのかを見破る判別器 (discriminator)の2つニューラルネットにより構成される画像生成ためのニューラルネットである [43]。
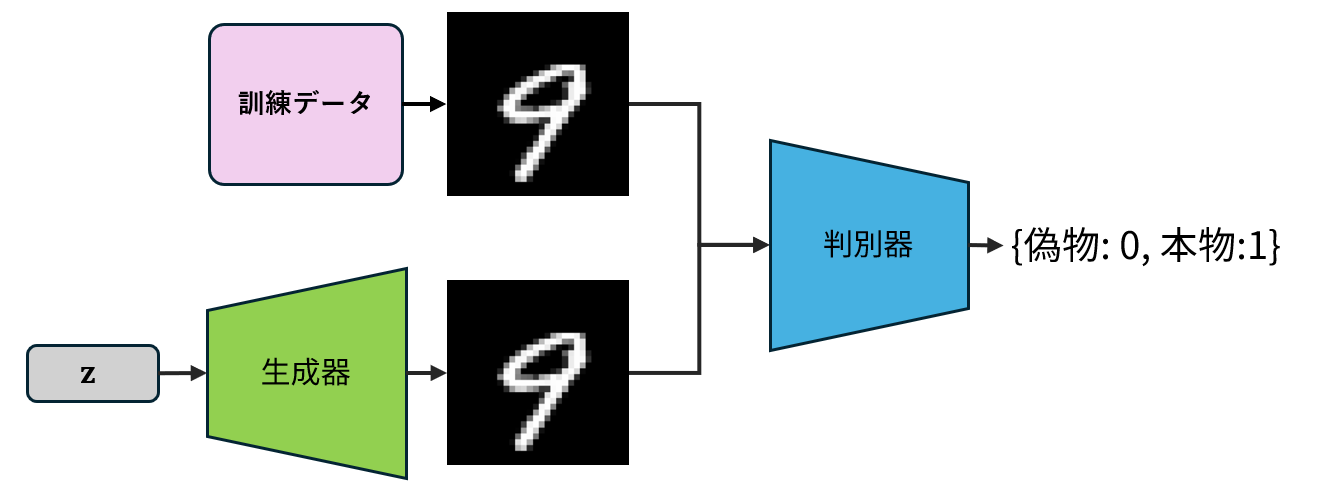
図 10.2 敵対的生成ネットワーク (GAN)の構造#
Ian Goodfellowにより提案されたオリジナルのGANは、必ずしも深層学習を用いる手法ではなかったため、GANのうち、深層学習を用いるものを区別してDCGAN (Deep Convolutional GAN)と呼ぶこともある [44]。
GANが、より高品質な画像を生成できるようになる学習の過程は、偽札を作る犯罪者と、それを見破る警察との関係に例えられる。
すなわち、生成器は「判別器が本物と勘違いするような画像の生成」を目指し、判別器は「本物の画像と生成器が作った画像を見分けること」を目指して学習を行う。
この学習は、数学的には次のミニマックス関数の最適化問題として定式化される。
この式が一体何を意味するのかもう少し詳しく見ていこう。
10.3.1. GANが目指すもの#
GANが最終的に達成したいのは、生成器により画像を生成する操作を、とある確率分布 \(p_G\) からのサンプリングに見立てた時に、この分布がデータの分布と一致する、すなわち \(p_G = p_\text{data}\) となることである。
GANの論文では、(10.4) の最適化が、2つの確率分布の差として、Jensen-Shannonダイバージェンスを最小化する問題と同義であることが述べられている。
Jensen-Shannon ダイバージェンス
Jensen-Shannonダイバージェンスは、2つの確率分布 \(p\) と \(q\) の間の距離を測る指標で、次のように定義される。
ただし、 \(m\) は確率密度 \(p\) と \(q\) の混合分布で \(m = (p + q) / 2\) である。
GANが目指す「Jensen-Shannonダイバージェンスの最小化」について順に見ていこう。
まず初めに、「理想的な判別器」について考える。理想的な判別器は、任意の生成器 \(G\) に対して次の量 \(V(G, D)\) を最大化することを目指す。
この式は、交差エントロピーのような式になっていて、\(V(G, D)\)を最大化すると、第一項は \(p_\text{data}\) が高い確率を取る箇所では \(D\)が1に近い値を、\(p_\mathbf{z}\)が高い確率を取る箇所では \(D\) が0に近い値を取るようなる。
通常、\(a, b \in \mathbb{R}\)が \(a \neq 0\), \(b \neq 0\)を満たすとすると、 \(a \log y + b \log (1 - y)\) は \(y \in [0, 1]\) の範囲で \(y = \frac{a}{a + b}\)で最大値を取る。
従って、最適な判別器 \(D_G^{*}\) は任意の画像 \(\mathbf{x}\) について
を満たす。
任意の \(G\)について、最適な\(D_G^{*}\) を与えることができたので、(10.4) を \(G\) に関する指標として \(C(G)\) と書くことにすると、\(C(G)\) は、次のような式で与えられる。
ここで、
であって、同様に \(\mathbb{E}_{\mathbf{x} \sim p_G}\) も書き直せるので、結局、\(C(G)\) は次のように書ける。
Jensen-Shannonダイバージェンスは \(p_\text{data} = p_G\) のときに最小の0を取る。
以上から、(10.4) を最適化する操作は、\(p_\text{data}\) と \(p_G\) の間のJensen-Shannonダイバージェンスを最小化する操作と同等であることが確認できた。
10.3.2. モード崩壊#
GANの画像生成の過程は偽札を作る犯罪者と、それを見破る警察の関係に例えられると、本節の冒頭で述べた。
しかし、あなた自身が偽札を作る犯罪者だとして、日本で言うところの1000円札、5000円札、10000円札の全ての偽札を作りたいと思うだろうか?当然、本当に作りたいのは10000円札だけだろう。
このことと同様の問題がGANにも発生する。GANの生成器は、判別器に見破られない画像を作るために、自分の得意な画像だけを生成すれば十分なのである。そのため、GANの生成画像は、元の画像データセット全体を模倣するのではなく、その一部だけを模倣するようになってしまう。
このように似たような画像ばかりが生成されてしまう問題を モード崩壊 (mode collapse)と呼ぶ。
モード崩壊はGANの中心的な課題として、いくつもの研究で解決が試みられてきた。例えば、Wasserstein GAN (WGAN) [45] [46] や、スペクトル正規化[47]などの手法により、モード崩壊が緩和が試みられている。
WGANでは、通常のGANで用いられるJensen-Shannonダイバージェンスの代わりにWasserstein距離を用いることで、生成分布とデータ分布のずれをより安定に評価することを目指している。すると、訓練の過程において、生成分布がデータ分布にどの程度近づいているかが評価できるようになり、モード崩壊が緩和が期待できる。
ただし、Wasserstein距離は、訓練の過程でその都度生成される画像に対して計算することは難しいため、生成画像と訓練データの画像に対して何らかのスコアを与え、その差をWasserstein距離の近似値として用いる (より厳密には、この差がWasserstein距離の双対表現に対応する)。
この際、スコア付けを担当するのが従来のGANの判別器に相当するcritic (評論家という意味)である。ただし、判別器が無制限に大きい、あるいは小さいスコアを付けることを許すと、少ししか違わない画像に対して、非常に大きなスコアの差が生じてしまう可能性がある。
そこで、画像の差に対してスコアの差が必要以上に大きくなりすぎないように、判別器の関数が1-Lipschitz連続であることが必要になる。
元のWGANでは、この制約を重みのクリッピングによって実現していたが、WGAN-GPでは勾配ペナルティを導入することで、Lipschitz定数の制約を試みる。また、スペクトル正規化は、各層の重み行列のスペクトルノルムを制御することで、判別器に対応する関数のLipschitz定数を抑え、GANの学習を安定化する手法である。
10.4. 拡散モデル#
拡散モデル (diffusion model)は、2020年台に登場した新しいタイプの生成モデルで、非常に高精細な画像を生成できることで注目を集めている。
以下では、拡散モデルの中でもDenoising Diffusion Probabilistic Model (DDPM) [48] と呼ばれるモデルを中心に説明する。
拡散モデルのポイントは、ある画像に徐々にノイズを加えていくと、最終的には完全なノイズ画像と見分けがつかないような画像になる、という点にある。

図 10.3 MNISTの数字画像にノイズを付加する様子#
そこで反対に、完全なノイズ画像から徐々にノイズを取り払っていけば、鮮明な画像が得られそうだ。このアイディアに基づき、拡散モデルでは、ノイズを少しだけ取り払う操作をニューラルネットで行い、完全なノイズ画像を徐々に生成画像に近づけていく。
この考え方を数式を用いて表してみよう。まず、訓練データに含まれる画像を \(\mathbf{x}_0\) とし、時刻 \(t\) とともに徐々にノイズが増えていくこととする。
DDPMでは、時刻 \(t\) におけるノイズ画像 \(\mathbf{x}_t\) が次のように表せると考える。
ここで \(\beta_t\) は、時刻 \(t\) において付加されるノイズの強さを表す定数である。通常 \(\beta_t\) は、時刻 \(t\) が大きくなるにつれて大きくなるように設定される。
安直に考えると、このような膨大なステップを含むノイズ付与の過程の全てを追跡しながら、元の画像と復元画像の誤差を最小化するようにニューラルネットを学習しなければならないように思える。
しかし、DDPMでは、時刻 \(t\) までノイズを加えた画像 \(\mathbf{x}_t\) を元の画像 \(\mathbf{x}_0\) から直接サンプル可能で、具体的には次のような式を満たす。
従って、標準正規分布に従うノイズ \(\boldsymbol{\epsilon}\) を用いると、次のように書ける。
DDPMの訓練では、ニューラルネットに、ノイズ付き画像 \(\mathbf{x}_t\) と時刻 \(t\) を入力として、元の画像 \(\mathbf{x}_0\) に含まれるノイズ \(\boldsymbol{\epsilon}\) を予測する問題をニューラルネットに学習させる。
すなわち、ニューラルネットは次のような関数 \(\mathcal{L}\) を最小化する。
この式は、拡散モデルの学習を、「数百のステップのうちの1ステップ分に相当するノイズの予測」に関する教師あり学習として定式化している。そのため、画像に対するノイズ付与の過程や、ノイズ除去の全過程を一度に考える必要がない。
画像の生成時には、まず完全なノイズ画像 \(\mathbf{x}_T\) を標準正規分布からサンプルする。その後、ニューラルネットが予測したノイズを用いて、 \(\mathbf{x}_{T-1}\), \(\mathbf{x}_{T-2}\), ..., \(\mathbf{x}_0\) と徐々にノイズを取り払っていくと、最終的に得られる 画像 \(\mathbf{x}_0\) が生成画像となる。
10.4.1. Classifier Free Guidance#
前述のCVAEと同様、拡散モデルを用いても条件付きの画像を生成が可能である。
ただし、拡散モデルの定式化から、直接的に条件付きの画像生成を行おうとすると、異なるノイズレベルの画像に対して、その画像がどの条件に対応するのかを判別する分類器を事前に学習して置かなければならない。
これは実際には、かなり手間がかかるため、拡散モデルを用いた条件付き画像生成では classifier free guidance (CFG) と呼ばれる方法 [49] が広く用いられている。
条件を表す変数を \(\mathbf{c}\) とし、拡散モデルで条件付き画像生成を考える場合、ニューラルネットには、ノイズ付き画像 \(\mathbf{x}_t\) と時刻 \(t\) だけでなく、条件 \(\mathbf{c}\) も入力する必要がある。
CFGでは、訓練時に一定の確率で条件 \(\mathbf{c}\) を空の条件 \(\varnothing\) に置き換える。例えば \(\mathbf{c}\) がクラスラベルを表すone-hotベクトルなら、訓練時に一定の確率でそのベクトルを全て0のベクトルに置き換える。
この方法で、同じニューラルネットに対し、条件ありのノイズ予測
と、条件なしのノイズ予測
の両方を学習させる。
画像を生成時には、条件ありの予測 \(\boldsymbol\epsilon_\mathbf{c}\) と条件なしの予測 \(\boldsymbol\epsilon_{\varnothing}\) の線形結合により、条件をどの程度強く反映させるかを調整する。
ここで、\(w\) は guidance scale と呼ばれる係数であり、条件をどの程度強く反映させるかを調整する。
通常、\(w\) を大きくすると、生成画像は条件 \(\mathbf{c}\) により強く反映する。一方で、\(w\) を大きくしすぎると、画像の多様性が低下したり、不自然な画像が生成される危険性が高まる。
CFGの重要な点は、条件あり・条件なしの2つのモデルを別々に用意するのではなく、訓練時に一定確率で条件を欠損させながら1つのモデルを学習することで、生成時に条件の効かせ方を調整できる点にある。
生成時には条件あり・条件なしの2回のネットワーク評価が必要になるものの、クラスラベルやテキストなどの条件が柔軟に扱いやすくなる。
この考え方は、テキストから画像を生成するマルチモーダル生成と相性が良い。テキストエンコーダによって入力文を特徴ベクトル \(\mathbf{c}\) に変換し、その特徴を条件として拡散モデルに与えれば、テキストに沿った画像生成が可能になる。
さらにCFGを用いることで、生成時にテキスト条件をどの程度強く反映するかを調整できる。
10.4.2. 拡散モデルに基づくマルチモーダル生成#
近年では、OpenAIのDALL-E (URL) やGoogleのImagen (URL), Stability AIのStable Diffusion (URL)など、テキストから画像を生成する マルチモーダル生成モデルが注目を集めている。
ここでは、論文として公開されている情報から、これらのテキストに基づく画像生成モデルを簡単に紹介しよう。
DALL-E#
OpenAIが、2021年の2月に公開したテキストから画像を生成するモデルが DALL-E で、そのおおよその内容は [50]にまとめられている。
オリジナルのDALL-Eは拡散モデルに基づく手法ではなく、テキストを画像に翻訳するようなTransformerベースのモデルを採用している。
従って、テキスト情報がトークン列としてTransformerに渡されると、画像情報に対応するトークンが順に出力される。
ただし、画像はそのままだとトークン列としては扱いづらいので、discrete VAE (dVAE) と呼ばれるVAEの拡張を用いて、画像と離散的なトークン列の相互変換を行う。
DALL-Eの後継モデルである DALL-E 2 は、DALL-Eの公開からおよそ1年後の2022年4月に公開されてたモデルで、こちらは拡散モデルに基づく技術である[51]。
特徴的な点としては、組になった画像情報とテキスト情報に類似した潜在ベクトルを与えるCLIP (Contrastive Language-Image Pretraining) の利用が挙げられる。
DALL-E 2では、入力のテキスト情報からCLIPを用いて「言語的な潜在ベクトル」を得た後、それを「画像的な潜在ベクトル」へと変換する処理を行う。この処理はpriorと呼ばれるニューラルネットで行われる。
その後、得られた画像的な潜在ベクトルは、GLIDE [52] (Generative Language-Image Diffusion for Editing)のようなCLIP特徴に基づいた画像生成を行う拡散モデルに入力され、最終的な画像を得る。
Imagen#
Imagenは、DALL-E 2の公開からおよそ1ヶ月後の2022年5月にGoogleが公開したマルチモーダルモデルである [53]。
Imagenは、DALL-E 2のように、すでに画像とテキストが関係づけられているCLIPのようなモデルを利用せず、T5-XXLという大規模な言語モデル (ただし、今では中規模程度かもしれない)を使ってテキストから特徴を抽出する。
あとは、拡散モデルが、ノイズ画像から画像を復元する過程で、テキストから得られた特徴ベクトルを条件として与えることで、テキストに沿った画像を生成する。
Imagenは、テキストに沿った画像を生成するために、前述のCFGを採用しており、これにより、画像生成時には、どの程度テキストに沿った画像を生成するかを調整できる。
また、Imagenは最初に解像度の小さな画像を生成したあとに、その解像度を拡散モデルを用いて徐々に大きくするという方式を取っており、必要に応じて高解像度画像の生成が可能になっている。
Stable Diffusion#
これら3つのモデルの中で最も知名度が高いであろう Stable Diffusion は、2022年8月にStability AIが公開したマルチモーダル生成モデルである。
Stable DiffusionはDALL-E 2とImagenの両方の特徴を持ったモデルで、テキストからの特徴抽出と、画像生成のそれぞれにおいて、従来モデルの優れた点を取り入れている。
まず、テキストからの特徴抽出には、DALL-E 2と同様に事前学習済みのCLIPを利用する。このCLIP特徴は、Imagenと同様にCFGの枠組みで画像生成を担当する拡散モデルに渡される。
しかし、Stable Diffusionが、従来のモデルと最も異なっている点は、潜在空間拡散 (latent space diffusion) [54]と呼ばれる技術により、拡散モデルの計算量の問題を解決している点である。
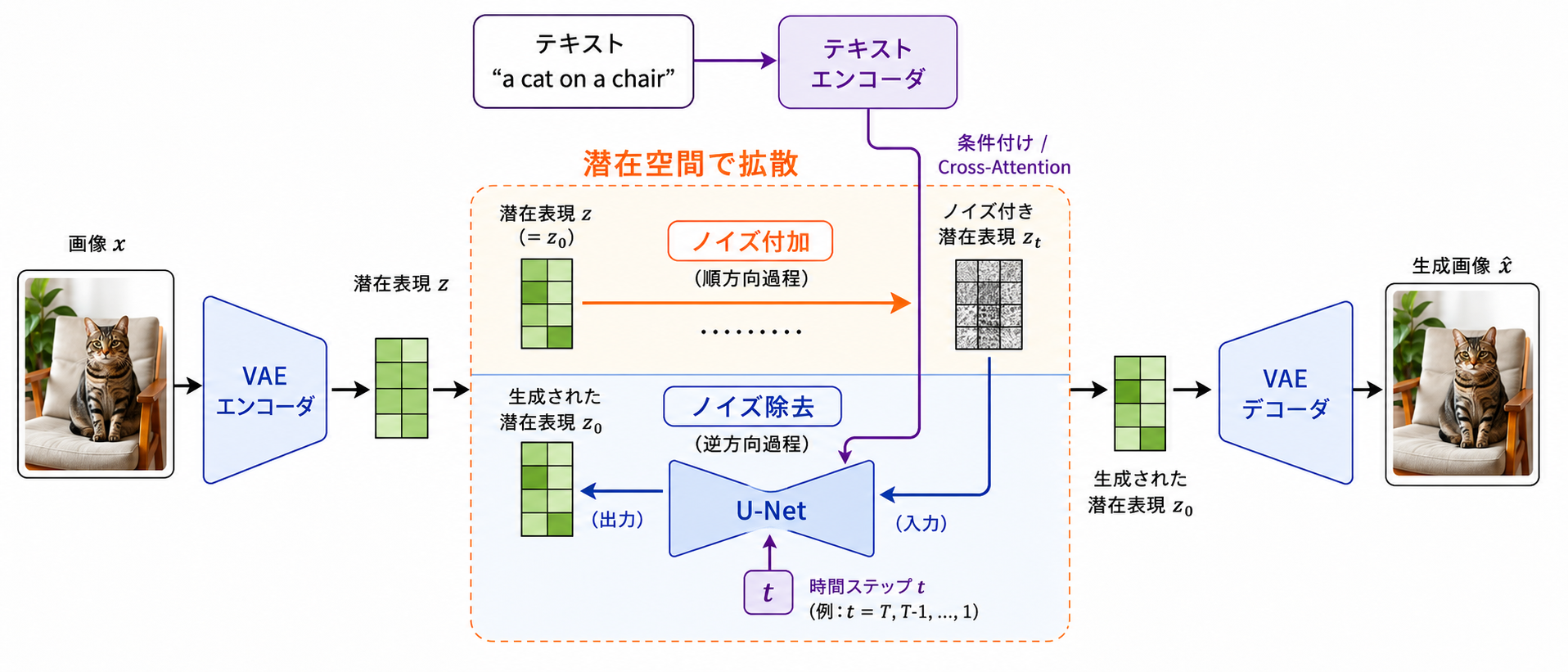
図 10.4 Stable Diffusionの潜在空間拡散モデルの概念図#
潜在空間拡散モデルは、学習済みのVAEを用いて得られる潜在ベクトルを拡散モデルを用いて再現する。この潜在ベクトルのための拡散モデルにおいて、テキスト特徴を用いたCFGによる条件付けが行われる。
また、Stable Diffusionは、他の2つのモデルと異なり、モデル自体がHugging Faceのようなプラットフォームで公開されており、様々な目的で広く利用可能である。
それ故、Stable Diffusionは、それ以後の研究において、いわゆる基盤モデルとして、様々な応用に広く利用されている。
モデル |
画像生成の仕組み |
テキスト条件の扱い |
特徴 |
|---|---|---|---|
DALL-E |
画像を離散トークン列として順次生成 |
テキストトークンと画像トークンを同系列で処理 |
拡散モデルではなくTransformerベース |
DALL-E 2 |
CLIP特徴を条件とする拡散モデル |
テキスト特徴を画像特徴に変換 |
CLIP潜在空間と拡散モデルを接続 |
Imagen |
拡散モデル |
T5-XXLのテキスト特徴を条件に利用 |
言語モデルの強さが画像品質に効くことを示した |
Stable Diffusion |
潜在空間上の拡散モデル |
CLIP系テキスト特徴を注意機構で考慮 |
計算効率と公開性により広く普及 |
まとめ: 生成のための深層学習
画像生成は深層学習の出現により大きく進歩した分野でVAEやGAN、拡散モデルなど、複数の技術が提案されている
VAEは変分Bayesの枠組みを用いて、変分限界 (ELBO)を最大化するようにニューラルネットを訓練する
GANは、生成器と判別器の2つのニューラルネットを競わせる形で、より高品質の画像を生成・判別するように訓練する
拡散モデルは、ノイズを徐々に取り除く処理をニューラルネットに学習させることで、最終的に高品質の画像を生成する
10.5. プログラミング演習#
レポートは テンプレートファイル を使用して作成してください。また、ファイル名は 「(7桁の学籍番号)_第x回_画像処理レポート.docx」 (xの部分は何回目の課題なのかを記入)に変更してください。
課題作成上の注意
課題を作成する際には、プログラムは別に .py ファイルで作成して、本レポートと一緒に圧縮したうえで提出してください。また、Jupyter Notebook形式のファイル (拡張子が.ipynb)のものは受け付けません。
加えて、プログラムを添付したのみで内容に関する説明や結果に関する考察のないもの、単なる結果の羅列になっているもの(またはそのように見えるもの)は採点しませんのでご注意ください。
DCGANの学習
以下のURLにあるGoogle Colabのノートブック上でDCGANの学習パラメータを変化させた時、生成される画像の品質がどう変化するかを調査せよ。
特に、潜在空間の次元数 (sample_dims)、ネットワークの大きさ (base_filters)、ならびにラベル平滑化の強さ (label_smooth) の3つのパラメータを変化させたときの生成画像の品質の変化を調査すること。