9. 深層学習#
深層学習 とは多くの層からなる階層型ニューラルネットを用いる機械学習モデルのことである。
本節では、深層学習の歴史を振り返りながら、深層学習の基礎となる連想記憶の考え方と、分類のための深層学習モデルについて見ていこう。
クイズ
現在、深層学習に基づく画像分類の精度は、対象にもよるが、一般的な人間や専門家の精度を上回ることもある。一方で、画像診断などの場面では、依然として人間の専門家が最終的な判断を下すことが多い。この背景にはどのような課題があると考えられるか?
参考資料
『ディジタル画像処理 改訂第二版』 P.293 第13章 深層学習による画像認識と生成
『深層学習』 編: 神嶌 敏弘, 著: 麻生 英樹ら
人工的なニューラルネット (artificial neural network)は、人間の脳におけるニューロンのシナプスを介した情報伝達網 (biological neural network)を模したモデルとして1950年代から研究されていた。
多層のニューラルネットの考え方を最初に提唱したのは、当時NHKの放送技術研究所の研究員であった福島邦彦 が提案した ネオコグニトロン (neocognitron) であると言われている。驚くべきことに、その論文は1980年に出版されている [30]。
これは2024年にノーベル物理学賞を獲得したGeoffrey Hintonの代表研究である誤差逆伝搬の論文[31] (1986年発表) や、John HopfieldのHopfieldネットワークの論文[32] (1982年発表)よりも前である。
ただし、ネオコグニトロンが提案された1980年代は、ニューラルネットワークの持つ多数のパラメータを上手く最適化する手法がなく、その時代には今で言う深層ニューラルネットの実現は難しいと考えられていた。事実、当時のニューラルネットは入力層、隠れ層、出力層の三層から成るニューラルネットが主流であった。
しかし、2010年代に入ると、それまで下火だったニューラルネットが再び注目を集めることになる。
それまで地道に続けられていたニューラルネットワークの研究の中で、過学習の抑制や最適化時の勾配消失の対処法が明らかになり、加えて、GPUを用いた汎用計算であるGPGPU (General Purpose Computing on GPU)により並列計算の効率が大幅に上昇したことで、ニューラルネットワークを取り巻く環境が徐々に変化してくる。
ImageNetと呼ばれる大規模画像データセットの識別チャレンジであるILSVRC (ImageNet Large Scale Visual Recognition Challenge)において、2012年にトロント大学のGeoffrey Hintonらの研究チームが、AlexNet (筆頭著者のfirst nameから)と呼ばれるニューラルネットを用いて優勝する [33]。
AlexNetはtop-5 エラー率 (正解ラベルが予測ラベルのトップ5までに含まれない割合) はわずか15.3%を達成したが、その性能は2位チームのエラー率26.2%を大幅に上回るものであった。ちなみに、この時に2位に入賞したチーム(東京大学の研究グループ)が用いた手法はSIFT、Fisherベクトル、サポートベクトルマシンを組み合わせたものであった。
この優勝を皮切りに、2014年には、Googleのチームが GoogLeNet というネットワークで優勝し、準優勝は、オックスフォード大学のチームが提案したVGG-Net (VGGは研究グループ名)であった。2015年には、Microsoftのチームが ResNet というネットワークで優勝した。
すると、画像認識の分野では深層学習が盛んに研究されるようになり、その応用が生成モデルや強化学習など、様々な分野に広がって現在に至る。
9.1. ニューラルネット#
本節の冒頭で述べた通り、ニューラルネットは生物の脳神経系に着想を得た計算モデルである。
生物の脳内では複数のニューロンがシナプスで結合されており、ニューロンはシナプスを介して他のニューロンと情報をやり取りしている。ニューロンは、他のニューロンからの入力信号がある閾値を超えると、活動電位と呼ばれる信号を発生させる。この活動電位は、他のニューロンに伝達され、次のニューロンの活動を引き起こす。
この活動を計算機で模倣したものが ニューラルネットワーク (artificial neural network)である。通常、生物のニューロンは多くの別のニューロンと結合していて、その結合網は複雑なグラフ構造となっているが、これを計算機上で模倣しようとすると処理が複雑になりすぎてしまう恐れがある。
そのため、現代につながるニューラルネットでは、ニューロンを層状に配置し、隣接する層と層の間での情報伝達を考える 階層的ニューラルネット を用いるのが一般的である。
9.1.1. 階層型ニューラルネット#
ここでは単純な階層型のニューラルネットとして、入力層、隠れ層、出力層の3つの層を持つモデルを考えよう。
各層のニューロンは自分が発火しているのかしていないのかを表す0か1かの数値を持っている。これを数学的に表すなら、入力層、隠れ層、出力層のそれぞれがもつ情報をベクトル \(\mathbf{x} \in \{ 0, 1 \}^{N_1}\), \(\mathbf{h} \in \{ 0, 1 \}^{N_2}\), \(\mathbf{y} \in \{ 0, 1 \}^{N_3}\) で表すことになる (\(N_1\), \(N_2\), \(N_3\)はそれぞれの層のニューロン数)。
今、とある層のニューロンが次の層のニューロン全てに接続されているとすれば、そのニューロン間の接続の強さを行列で表すことができる。すなわち、入力層から隠れ層への接続の強さは \(\mathbf{W}_{1} \in \mathbb{R}^{N_2 \times N_1}\)、隠れ層から出力層への接続の強さは \(\mathbf{W}_{2} \in \mathbb{R}^{N_3 \times N_2}\) のように表すことができる。
情報を受け取った各ニューロンは、受け取った値が、あるしきい値 (例えば0.5)を超えていたら1、そうでなければ0を取るような活性化される。
このような各ニューロンの活性化状態を決定する関数を 活性化関数 と呼ぶ。ここで、活性化関数を
のように書くことにすると、隠れ層の各ニューロンの発火状態は、入力層のニューロンの発火状態を用いて次の式で書き表せる。
同様に、出力層のニューロンの発火状態は、隠れ層のニューロンの発火状態を用いて次の式で書き表せる。
このように入力から出力に向かって情報を順々に伝達する操作を フィードフォワード (feedforward)と呼ぶ。
機械学習モデルとしてのニューラルネットは、訓練データセット上で定義された入力 \(\mathbf{x}\) に対して、それにふさわしい出力 \(\mathbf{y}\) を返すように訓練される。従って、この3層のニューラルネットでは \(\mathbf{W}_{1}\), \(\mathbf{W}_{2}\)の2つの行列を訓練データに合うように最適化すれば良い。
より一般的には、単なる行列 \(\mathbf{W}\) の掛け算だけではなく、バイアスベクトル \(\mathbf{b}\) も考えて、
のように表すことが多いが、ここでは説明を簡単にするために、バイアスベクトルは考えないことにする。
9.1.2. 誤差逆伝播法#
誤差逆伝搬法 (backpropagation) [31] は、階層型ニューラルネットを効率的に訓練するためのテクニックの一つである。
ここでは、単純な二値分類問題を例にとって、誤差逆伝搬法の考え方について説明する。
まず、ニューラルネットが表す関数を微分するために、不連続なしきい値処理を行っていた活性化関数 \(\sigma\) を連続的な関数に置き換える。
しきい値処理を滑らかな関数で置き換えたシグモイド関数
を用いると、活性化関数が微分可能になる。
すると、出力層の発火状態 \(\mathbf{y}\) を、入力層の発火状態に関する連続的な関数として表すことができるようになる。具体的には、シグモイド関数 \(\sigma\) を用いて、次の関係式が得られる。
今回は二値分類問題を考えているので、出力層 \(\mathbf{y}\) の各ニューロンに対して、各要素の値が0か1かとなっている教師信号 \(\mathbf{t} \in \{ 0, 1 \}^{N_3}\) を用意する。
損失関数 \(\mathcal{L}\) をニューラルネットからの出力 \(\mathbf{y}\) と教師信号 \(\mathbf{t}\) の間の二値交差エントロピーで表すと次のようになる。
ここで損失関数 \(\mathcal{L}\) の値は実数値であり、 損失関数の値を最小化することがニューラルネットの訓練の目的 である。
損失関数 \(\mathcal{L}\) は入力 \(\mathbf{x}\) や中間状態 \(\mathbf{h}\) の関数であるのと同時に、ニューラルネットのパラメータである重み行列 \(\mathbf{W}_{1}\), \(\mathbf{W}_{2}\) に関する関数でもある。
従って、 損失関数 \(\mathcal{L}\) を重み行列 \(\mathbf{W}_{1}\), \(\mathbf{W}_{2}\) に関して微分し、その勾配を求めると、最急降下法などのアルゴリズムによって、\(\mathcal{L}\) を最小化するような \(\mathbf{W}_{1}\), \(\mathbf{W}_{2}\) が求められる。
例えば、損失関数の値 \(\mathcal{L}\) を重み行列 \(\mathbf{W}_{2}\) に関して微分すると、次のような式が得られる。
同様にして、出力 \(\mathbf{y}\) を重み行列 \(\mathbf{W}_{1}\) に関して微分すると、次のような式が得られる。
ここで大事なことは、(9.2)と(9.3)は一部の項 (\(\partial \mathcal{L}/\partial \mathbf{y}\)) が共通しているという点である。
実は、階層型ニューラルネットの入力に近い方の層の変数による微分は、出力に近い方の変数による微分の値を用いて、出力に近い方から順に計算できる。これは、ニューラルネットが複数の関数の合成となっているためで、合成関数の微分の 連鎖律 (chain rule)が利用できるためである。
この連鎖律を利用して、出力に近い方の層から順に微分を計算していく手法を 誤差逆伝播法 と呼ぶ。
まとめ: ニューラルネット
ニューラルネットは元々、生物の脳神経系に着想を得た計算モデルであった
現在は複数の層を持つ階層型ニューラルネットが主流である
ニューラルネットのパラメータの最適化は誤差逆伝搬法を用いて効率化できる
9.2. 連想記憶#
ニューラルネットに関する研究において、今日の深層学習に大きな影響を与えたものはいくつもあるが、その中でも特に重要なものとして、2024年にノーベル物理学賞を受賞したJohn Hopfieldの Hopfieldネットワーク [32]、Geoffrey Hintonの 制限Boltzmannマシン (Restricted Boltzmann Machine, RBM) [34] について紹介しよう。
これら2つの技術は、ニューラルネットに与えられた複数の情報を記憶させる 連想記憶 のための手法である。考えてみると、ものごとの認識や生成というのは、人間の場合も何らかの過去の記憶を頼りにしていることが多い。その意味で、これらの2つの研究が提案した連想記憶の技術は、今日の深層学習モデルが行う認識や生成の基礎であるとも言える。
9.2.1. Hopfieldネットワーク#
Hopfieldネットワークは、1982年にJohn Hopfield氏が提唱した、連想記憶 (associative memory)のためのニューラルネットである。
Hopfieldネットワークは、複数のニューロンを持ち、全てのニューロンがその他の全てのニューロンと結合している。各ニューロンは自分以外のニューロンに情報を伝達して、次の状態へと遷移する。
この時、Hopfieldネットワークの各ニューロンは、生物のニューロンにおける学習則の一つである Hebb則 (Hebbian rule)に着想を得た情報の伝達を行う。
Hebb則とは、シナプスにおいて情報を発出する側の前細胞と、情報を受け取る側の後細胞の間での結合の強化に関する学習則である。具体的には次のようなものである。
とある前細胞Aが後細胞Bに情報を伝達し、結果として後細胞Bが発火した場合、前細胞Aと後細胞Bの間の結合が強化される。
Hebb則を数学的に表現すると、\(n\)個の前細胞の発火状態 \(\mathbf{x} \in \{ 0, 1 \}^n\) と、\(m\)個の後細胞の発火状態 \(\mathbf{y} \in \{ 0, 1 \}^m\) の間で、情報の伝達を表す行列 \(\mathbf{W} \in \mathbb{R}^{m \times n}\) が次のように変化する。
この式で \(t\) は時間を表し、各時刻で細胞同士の結合の強さが更新されることを意味する。
HopfieldネットワークにおけるHebb則では、前細胞や後細胞などの区別はなく、(9.4)を簡易化した次のような式を用いる。
これを離散的に表し、行列 \(\mathbf{W}\) の更新式として次のように表す。
ただし、\(\gamma\) は学習率を表すパラメータである。
Hopfieldネットワークで扱う発火状態は-1か+1のいずれかの値をとる (つまり \(\mathbf{x} \in \{ -1, +1 \}^n\)) 。また、各ニューロンは自分自身には情報伝達をしないので、 \(\mathbf{W}\) の対角成分は常に0であるとする。
Hopfieldネットワークは複数の-1と+1からなるパターンを記憶することができ、そのパターンに似たノイズを含む入力を与えると、ニューロンの発火状態が記憶したパターンに収束するという性質を持つ。
実際に、Hopfieldネットワークに0, 1, 2の数字を模した5×5のパターンを記憶させ、その後、ノイズ付きの入力を与えて得られた画像を以下に示す。
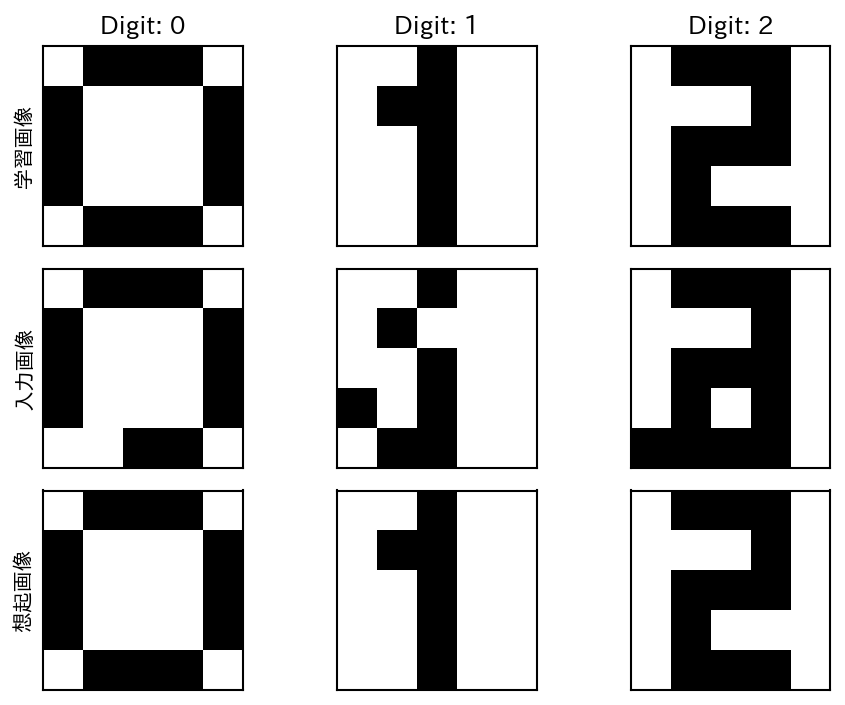
図 9.1 Hopfieldネットワークによる数字の想起結果#
このように記憶するデータの数が比較的少数で、なおかつノイズの量が少ない場合については、Hopfieldネットワークが正しくパターンを記憶できていることが分かる。
9.2.2. 制限Boltzmannマシン (RBM)#
制限Boltzmannマシン (Restricted Boltzmann Machine, RBM) は、1986年にGeoffrey Hinton氏が提唱した、確率的な連想記憶モデルであり、Hopfieldネットワークを確率的な表現を用いて拡張したものと位置づけられる。
RBMの前身であるBoltzmannマシンは、Hopfieldネットワークと同様に、全てのニューロンが他の全てのニューロンと結合しているニューラルネットであった。一方で、「制限」Boltzmannマシンのニューラルネットは、可視層 (visible layer)と隠れ層 (hidden layer)の2つの層を持ち、可視層と隠れ層のニューロンは互いに結合したような階層的ニューラルネットになっている。
今、RBMの可視層が持つニューロンの状態を \(\mathbf{x} \in \{ 0, 1 \}^{N_1}\)、隠れ層が持つニューロンの状態を \(\mathbf{h} \in \{ 0, 1 \}^{N_2}\) と表す。この際、ニューロンの状態を-1か+1かで表していたHopfieldネットワークと異なり、ニューロンの状態が0か1かで表されていることに注意してほしい。
RBMは可視層で情報を受け取ると、それを重み行列 \(\mathbf{W} \in \mathbb{R}^{N_1 \times N_2}\) とバイアスベクトル \(\mathbf{c} \in \mathbb{R}^{N_2}\) に基づいて用いて隠れ層に伝達する。
RBMは、Hopfieldネットワークと異なり、隠れ層に伝達された情報が、シグモイド関数 \(\sigma\) を使って確率的に発火するようなモデルになっている。そのため、隠れ層に伝達された情報は0から1の間の実数値で、各ニューロンの発火確率を表す。
隠れ層のニューロンは、さらにその情報を可視層に伝達する。重み行列 \(\mathbf{W}\) が再利用され、バイアスベクトルとしては別の \(\mathbf{b} \in \mathbb{R}^{N_1}\) を用いる。
可視層ではシグモイド関数を用いて各ニューロンの発火確率が計算される。最終的に、この発火確率が0.5より大きければ、そのニューロンが発火しているとみなして出力を得る。
RBMは連想記憶のモデルであるので、入力された画像がパラメータ \(\Theta = \{ \mathbf{W}\), \(\mathbf{b}\), \(\mathbf{c} \}\) によって再現されることを期待している。
この際、ある入力画像 \(\mathbf{v}\) に対して、RBMは次の同時分布を考える。
ただし、\(Z(\Theta)\) は \(p(\mathbf{v}, \mathbf{h} \mid \Theta)\) を正規化するための規格化定数で
とする。
この確率密度関数の定義には \(\mathbf{v}\) 同士または \(\mathbf{h}\) 同士の積は存在せず、これはRBMの構造において、可視層と隠れ層の間でだけ結合が存在することを示している。
このことから、一度、可視層が固定されれば、隠れ層のニューロン同士は独立に発火状態が決まるため、事後分布 \(p(\mathbf{h} \mid \mathbf{v}, \Theta)\) は次のように書ける。
同様に、事後分布 \(p(\mathbf{v} \mid \mathbf{h}, \Theta)\) も次のように書ける。
RBMでは、パラメータ \(\Theta = \{ \mathbf{W}, \mathbf{b}, \mathbf{c} \}\) に関する出力画像 \(\mathbf{v}\) の事後確率 \(p(\mathbf{v} \mid \Theta)\) を考え、この事後確率が真の確率密度分布 \(q(\mathbf{v})\) に近づくように、パラメータ \(\Theta\) する問題を考える。
ここで、確率密度分布同士の近さを図るために、次のKulback-Leiblerダイバージェンス (KLダイバージェンス)を導入する。
ここで、最適化するパラメータ \(W_{ij}\), \(b_i\), \(c_i\) のいずれかを表す変数として \(\theta\) を使い、(9.9)を \(\theta\) で微分する。 (9.9)の第1項はパラメータ \(\theta\) に依存しないので、次のように書ける。
これに (9.7) を代入して式を整理したい。まず、 (9.7) を周辺化して変数 \(\mathbf{h}\) を消去する。
(9.9)に、(9.10)と(9.8)を代入すると、次の式が得られる。
この式のようにKLダイバージェンスのパラメータ \(\theta\) に関する勾配が求まったら、あとは最急降下法の要領でパラメータを更新すればよいのだが、ここで一つ問題がある。それは第2項の期待値を解析的にも数値的にも計算することが困難、という点である。
この点を少し詳しく見ていこう。
まず、第1項は訓練データに含まれる画像を \(\mathbf{v}\) とすれば、\(q(\mathbf{v})\) は訓練データの分布そのものなので問題ない。また \(p(\mathbf{h} \mid \mathbf{v}, \Theta)\) についても、パラメータ \(\Theta\) が与えられれば、(9.5) を用いて計算できる。
従って、これらのサンプルに感する期待値は、訓練データからのサンプルを用いて計算可能である。
一方で、第2項の期待値計算のために用いる \(p(\mathbf{v}, \mathbf{h} \mid \Theta)\) を評価するには、任意の \(\mathbf{h}\) を考える必要があるため、この確率に関する期待値を求めるのは実質的に不可能である。
ここで、(9.7) の \(p(\mathbf{v}, \mathbf{h} \mid \Theta)\) の定義に話を戻そう。前述の通り、この定義では、\(\mathbf{v}\) 同士、または \(\mathbf{h}\) 同士の結合は存在せず、(9.5) と(9.6) を用いて 確率密度分布 \(p(\mathbf{h} \mid \mathbf{v}, \Theta)\) と \(p(\mathbf{v} \mid \mathbf{h}, \Theta)\) に従うサンプルを得ることはできる。
このようなケースでは、Gibbsサンプリングと呼ばれる手法をもちいて、 \(p(\mathbf{v}, \mathbf{h} \mid \Theta)\) に従うサンプルを近似的に取得することができる。Gibbsサンプリングの詳細については割愛するが、以下の操作によって、\(p(\mathbf{v}, \mathbf{h} \mid \Theta)\) に近似的に従うサンプルを得ることができる。
可視層のニューロンの状態を \(\mathbf{v}\) として与える。
(9.5) を用いて、隠れ層のニューロンの状態 \(\mathbf{h}\) を計算する。
(9.6) を用いて、可視層のニューロンの状態 \(\mathbf{y}\) を計算する。
\(\mathbf{y}\) の値を \(\mathbf{v}\) として2.に戻る。
ある回数だけ3.と4.を繰り返す。
このようにして得られた \(\mathbf{v}\) と \(\mathbf{h}\) の組み合わせは、\(p(\mathbf{v}, \mathbf{h} \mid \Theta)\) に従うサンプルとなるので、これを用いて(9.11)の第2項の期待値を近似的に計算すれば良さそうだ。
通常、Gibbsサンプリングによって十分な数のサンプルを取得して(9.11)の第2項の期待値を求める必要がありそうだが、RBMではこのサンプリングを少ない回数 \(k\) 回だけ行って近似する。
このようにして得られたサンプルを用いた勾配の近似法を コントラスティブ・ダイバージェンス法 (Contrastive Divergence, CD) と呼ぶ。興味深いことに、RBMの文脈では \(k = 1\) でも十分に良い学習が行えることが分かっている。
制限Boltzmannマシンに、先ほどと同様に0-9の数字を模した5×5のパターンを記憶させてみた結果が以下である。
以下の結果では、上の行にノイズ付の入力画像を、下の行に制限Boltzmannマシンによる出力画像を示した。
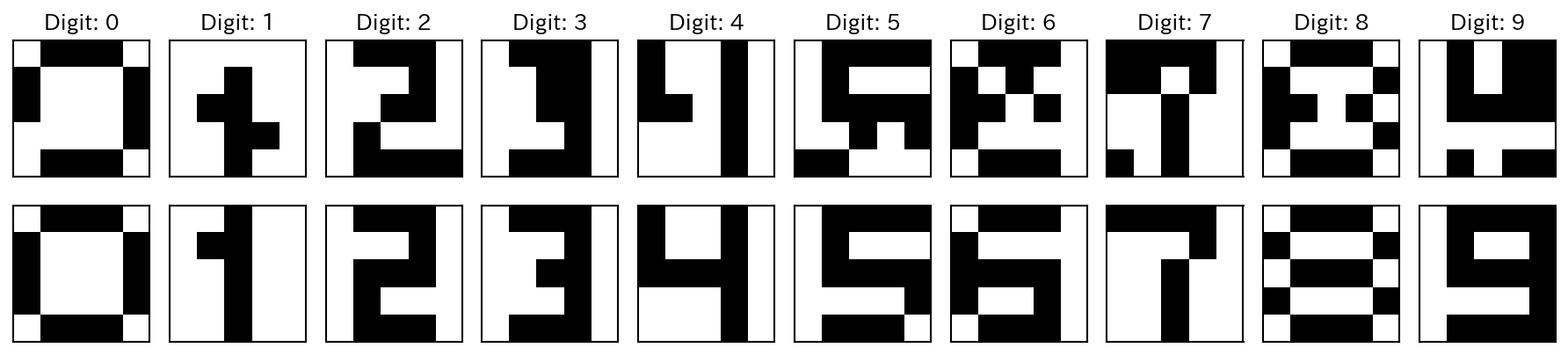
図 9.2 RBMによる画像の再構成結果#
今回はスペースの都合上、学習した画像は示していないが、RBMが学習したパターンを完璧に再現できていることを付け加えておく。
これら、HopfieldネットワークやRBMの考え方が基礎となり、深層Boltzmannマシン (Deep Boltzmann Machine, DBM) や深層信念ネットワーク (Deep Belief Network, DBN) といった、より深い階層を持つニューラルネットの研究が行われ、今日の深層学習へと繋がっていく。
まとめ: 深層学習への歩み
Hopfieldネットワークは、Hebb則に着想を得た連想記憶モデルである
RBMは可視層と隠れ層からなり、その間の情報伝達を確率的に表現した連想記憶モデルである
HopfieldネットワークやRBMは連想記憶のための古典的手法で、今日の深層学習の基礎を築いた
9.3. 深層化のための課題#
ここまでの流れのなかで発展した深層学習だが、初期の深層学習モデルはどのような構造だったのかを見ていこう。
本項ではまず、画像認識を主として提案された深層学習モデルについて見ていく (ただし、その用途を画像認識に限っているわけではない)。
9.3.1. 過学習#
一般に、機械学習モデルは、モデルの複雑さが増すほど、訓練データに対して過剰適合する傾向がある。この現象を 過学習 と呼ぶ。過学習が起こると、訓練データに対しては高い性能を示す一方で、訓練データに含まれないテストデータに対しては性能が低下することがある。
深層学習モデルは、層の数に応じてパラメータ数が増え、モデルが複雑になるため、過学習が起こりやすくなる。
例えば、少数の点に対して多項式を当てはめるとき、多項式の次数を上げすぎると訓練点にはよく一致する一方で、点の間で不自然に大きく振動することがある。これは、モデルの自由度が高すぎるために、データに含まれるノイズまで拾ってしまう典型例である。
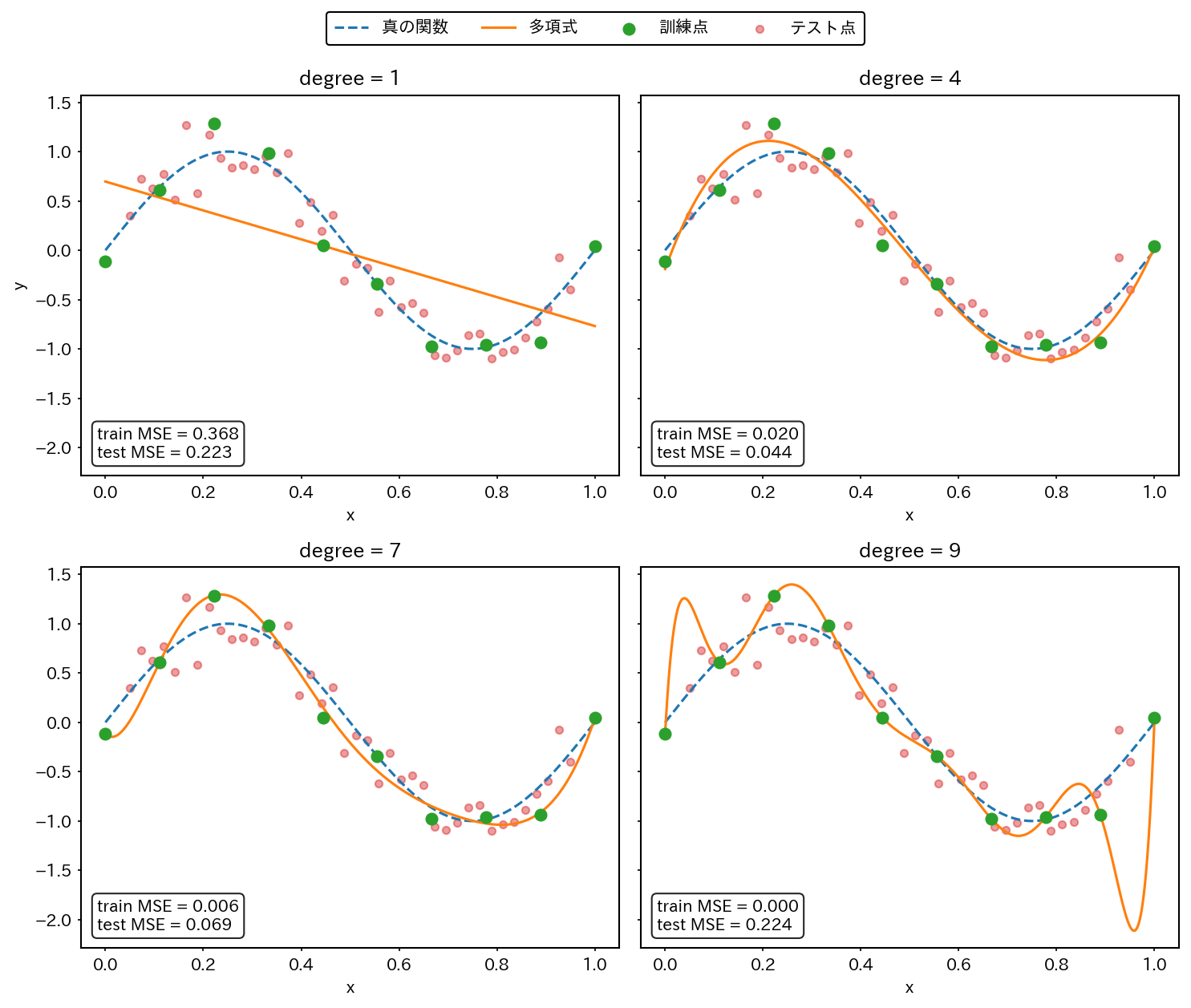
図 9.3 過剰適合の例#
上の例では、1次多項式は表現力が不足しており、9次多項式は訓練点にほぼ張り付く一方でテスト誤差が大きくなりやすい。これに対して中程度の次数では、訓練データと未知データの両方に対して比較的安定した振る舞いが期待できる。
このように、有限のサンプルに対して、モデルを当てはめる場合、実際のモデルの複雑さ、サンプル点の数、モデルの自由度のバランスを取る必要がある。特に深層学習モデルは、パラメータの数が多く、モデルの自由度が高いため、一般的に言って過学習のリスクが高い。
9.3.2. 勾配消失#
従来、ニューラルネットで用いられてきたシグモイドや双曲線正接といった活性化関数は、滑らかな関数ではあるが、入力の絶対値が大きい場合に、微分の値がほとんど0になるという性質を持っている。
例えば (9.1) で定義されるシグモイド関数の微分は次のように表される。
誤差逆伝搬法によるニューラルネットの学習では、出力層から入力層に向かって、誤差を伝播させながらパラメータを更新していく。この過程で、活性化関数の微分が何度も掛け合わされることになる。
すると、ニューラルネットの入力に近い側の層では、誤差逆伝搬の過程でパラメータの更新量が非常に小さくなり、効率的に学習が進まないという現象が起こる。これを 勾配消失問題 (vanishing gradient problem) と呼ぶ。
9.3.3. 帰納バイアス#
必ずしも課題というわけではないが、機械学習モデルが持つ帰納バイアスについても触れておこう。
帰納バイアス (inductive bias) とは、機械学習モデルが、訓練データから未知のデータに対して一般化する際に、どのような仮定を置いているかを表す概念である。単純な例として、線形回帰モデルであれば、データが直線や平面といった線形の構造を持つことを仮定している。これが線形回帰モデルの帰納バイアスである。
深層学習モデルを考える場合にも、各層で行われる計算や活性化関数などによって、ニューラルネットが何らかの暗黙的な仮定を持つことになる。例えば、以下で説明する畳み込みニューラルネットでは、画像の局所的な特徴を捉えようとする場合、それに必要なフィルタ処理は画像全体で同じで良い、という暗黙の仮定を持つ。
このような帰納バイアスは、比較的少数の訓練データから、帰納バイアスに沿った特徴を抽出するのに有利に働く一方で、帰納バイアスに沿わない特徴を抽出するのには不利に働くことがある。
9.4. 畳み込みニューラルネット#
本項では、画像処理に用いられることが多い畳み込みニューラルネットを中心に、モデル構造の変遷について見ていく。
9.4.1. LeNet-5#
LeNet-5 は1998年にYann LeCunらが手書き数字認識のために開発した5層の階層的ニューラルネットである。
LeNet-5は複数の 畳み込み層 と プーリング層 を持ち、最後に全結合層を持つという今日の畳み込みニューラルネット (CNN)の典型的な構造を持つ。
しかし、この当時はプーリング層として平均プーリング (現在は最大プーリングが一般的)、活性化関数に双曲線正接 (tanh)関数 (現在はReLUが一般的)を使っているなど、今日の一般的なニューラルネットと異なる部分も多かった。

図 9.4 LeNet-5の構造 (c) CC BY-SA 4.0 Wikipedia Commons#
LeNet-5の構造で興味深いのは、一部の全結合層が完全な全結合ではなく、ニューロン間の結合の一部が断ち切られている点である。
この構造は今日で言うところのドロップアウトにも共通する考え方であり、ニューロンの結合を制限して過学習を抑制している (ただし、今日のドロップアウトは確率的で、推論時には使われない)。
9.4.2. AlexNet#
AlexNetは、2012年にILSVRCで優勝した深層学習モデルである [33]。AlexNetは、LeNet-5と比較して、以下のような特徴を持つ。
5層の畳み込み層と3層の全結合層からなる (LeNet-5より層の数が多い)
活性化関数にReLUを採用
過学習を抑制するためにドロップアウトを採用
LeNet5から10年以上の時を経て提案されたAlexNetは、これらの現在では一般的になっている多くの特徴を階層型ニューラルネットに取り込んでいる。
特に注目すべきは、これまでシグモイド関数は双曲線正接関数が一般的であった活性化関数に ReLU (rectified linear unit)を採用した点である。
ReLUは、入力が0以下のときは0を出力し、入力が0より大きいときはそのまま出力するという単純な関数である。
この定義に従うと、ReLUの微分は0か1のいずれかであるため、数値誤差の蓄積による勾配消失の影響を抑えることができる。この工夫により、AlexNetは、より多くの層を持つニューラルネットの学習に成功した。
また、AlexNetで導入された ドロップアウト は、訓練時に、全結合層のニューロンの出力を確率的に0にする手法である。こうすることで、ニューラルネット上の情報の伝搬過程が特定の経路に過度に集中することを防ぎ、結果として過学習が抑制される。
9.4.3. より大規模な畳み込みニューラルネット#
AlexNet以降、VGG-16/19やGoogLeNet, ResNetなど、様々な深層学習モデルが提案された。一般に、ニューラルネットの層が深くなれば性能が向上する一方、上手く学習させることが難しくなる傾向がある。そのため、以下に挙げる手法では、層を深くするとともに学習を安定させるための工夫を導入している。
VGG-16/19#
VGG-16/19 は、Visual Geometry Group (VGG)というオックスフォード大学の研究グループが提案したニューラルネットで、画像認識の性能改善のために、どのような構造が重要なのかを検討した結果を反映している。
この研究の中の重要な発見の一つは、5✕5などの大きなカーネルを持つ畳み込み層を用いるよりも、カーネルサイズは3✕3に固定して、層の数を増やすほうが性能向上に効果的であることを示した点である。
畳み込みによって情報を集める範囲のことを 受容野 (receptive field) と呼ぶ。5✕5の畳み込み層は、入力画像の5✕5の範囲を受容野とする。一方、3✕3の畳み込み層を2層重ねても、同じく受容野を5✕5にすることができる。
これを、パラメータ数の観点で見ると、5✕5の畳み込み層は各入出力のニューロンの組み合わせに対して25個のパラメータを要するのに対し、3✕3の畳み込み層を2層重ねた場合には、18個のパラメータで同じ受容野をカバーできる。
さらに、各層の出力は活性化関数によって非線形変換されるので、3✕3の畳み込み層を2層重ねる方が、より複雑な特徴を抽出できる可能性がある。
また、同グループの研究では、AlexNetに用いられたLocal Response Normalization (LRN)が多層のニューラルネットでは、あまり効果がないことなども示されている。
GoogLeNet#
一方で、 GoogLeNet では、層を枝分かれさせて、異なるサイズの畳み込み層で特徴を抽出するInceptionモジュールを導入した。これによりGoogLeNetは22層のニューラルネットの学習を可能にした [35] 。
Inceptionモジュールでは、1×1、3×3、5×5畳み込みやプーリングを並列に適用し、異なるスケールの特徴を同時に抽出する。ただし、大きな畳み込みをそのまま多用すると計算量が増えすぎるため、GoogLeNetでは3×3や5×5畳み込みの前に1×1畳み込みを挿入し、チャネル数を削減してから高コストな畳み込みを行う。この1×1畳み込みは、画素位置ごとにチャネル方向の線形結合を行う層であり、空間解像度を保ったまま特徴チャネルを圧縮・変換する役割を持つ。
例えば、特徴マップサイズを \(H \times W\) 、入力チャネル数を \(C_\text{in}\) 、出力チャネル数を \(C_\text{out}\) とすると、\(k\times k\) 畳み込みの計算量はおおよそ
に比例する。したがって、事前に1×1畳み込みで入力チャネル数 \(C_\text{in}\) を \(C_r\) まで減らせば、必要な計算量は
まで減らすことができる。
バッチ正規化#
畳み込みニューラルネットそのものではないが、学習の安定化に重要な役割を果たした技術に バッチ正規化 (batch normalization) がある。バッチ正規化は、各層の出力を、訓練データのミニバッチごとに平均0、分散1に正規化する手法である [36]。
このようなデータの正規化は、入力となる訓練データに対しては一般に行われてきたが、ニューラルネットの各層の入力は訓練中のパラメータ更新によって変化してしまう。バッチ正規化の論文では、この変化を 内部共変量シフト (internal covariate shift) と呼び、これが学習の安定性を損なう一因であると指摘した。
バッチ正規化では、各層の出力に対してミニバッチ単位で平均と標準偏差を計算し、次の層の入力が平均0、分散1になるように正規化する。これにより、各層は前の層のパラメータ更新の影響を受けにくくなり、学習が安定化する。
また、各層の入力とバッチ正規化後の出力が平均0、分散1になるように正規化すると、誤差逆伝搬の過程で現れる勾配の値が1付近に保たれるようになり、勾配消失や勾配爆発の問題を抑制する効果もある。
ResNet#
さらに、Microsoftの研究チームが発表したResNetでは、50層以上の深いニューラルネットの学習に成功した [37]。ResNetの研究では、単なる畳み込み層の積み重ねで表現されるネットワークは一定以上の層の数を超えると学習が困難になることが示された。
そこで、各層が入力から全く新しい出力を作るのではなく、入力と出力との差分を学習する 残差学習 (residual learning) を導入した。
残差学習は、とある層の入力 \(\mathbf{x}_{l}\) と出力 \(\mathbf{x}_{l+1}\) を畳み込み層やバッチ正規化などの組み合わせで表される関数 \(F_l\) を用いて、次のように表す。
このとき \(F_l(\mathbf{x}_l)=\mathbf{0}\) であれば、このブロック全体は恒等写像 \(\mathbf{x}_{l+1}=\mathbf{x}_l\) に近い振る舞いをする。
したがって、深いネットワークの中に不要な変換が含まれていたとしても、それを明示的に新しい写像として学習するより、残差部分をゼロに近づける方が学習しやすいと考えられる。
ResNetの重要性は、層を増やすこと自体ではなく、深いネットワークにおいても恒等写像や小さな修正を表現しやすくした点にある。これにより、非常に深いネットワークでも勾配が伝わりやすくなり、最適化が安定しやすくなった。
9.5. Vision Transformer (ViT)#
Vision Transformer (ViT)は、それまで自然言語処理の分野で広く用いられていたTransformerと呼ばれるニューラルネットワークを画像向けに改良したモデルである [38]。
ViTそのものについて説明する前に、Transformerの基本的な構造について簡単に説明しておこう。
9.5.1. Transformer#
オリジナルのTransformerは、エンコーダ部とデコーダ部からなる構造を持ち、それぞれが、複数の 注意機構 (attention mechanism) と フィードフォワード・ネットワーク (FFN) から構成されている。

図 9.5 Transformerのアーキテクチャ
(出典: Transformer (deep learning) - Wikipedia)#
図 9.5 に示した機構は、2つの入力系列を受け取るエンコーダ部と、目的の系列を出力する1つのデコーダ部から構成されている。
注意機構#
注意機構は、元々、機械翻訳の文脈で提案された手法で、入力言語のどの部分に着目すると、出力言語の特定の部分を生成するのに役立つかを学習する仕組みである (下図参照)。
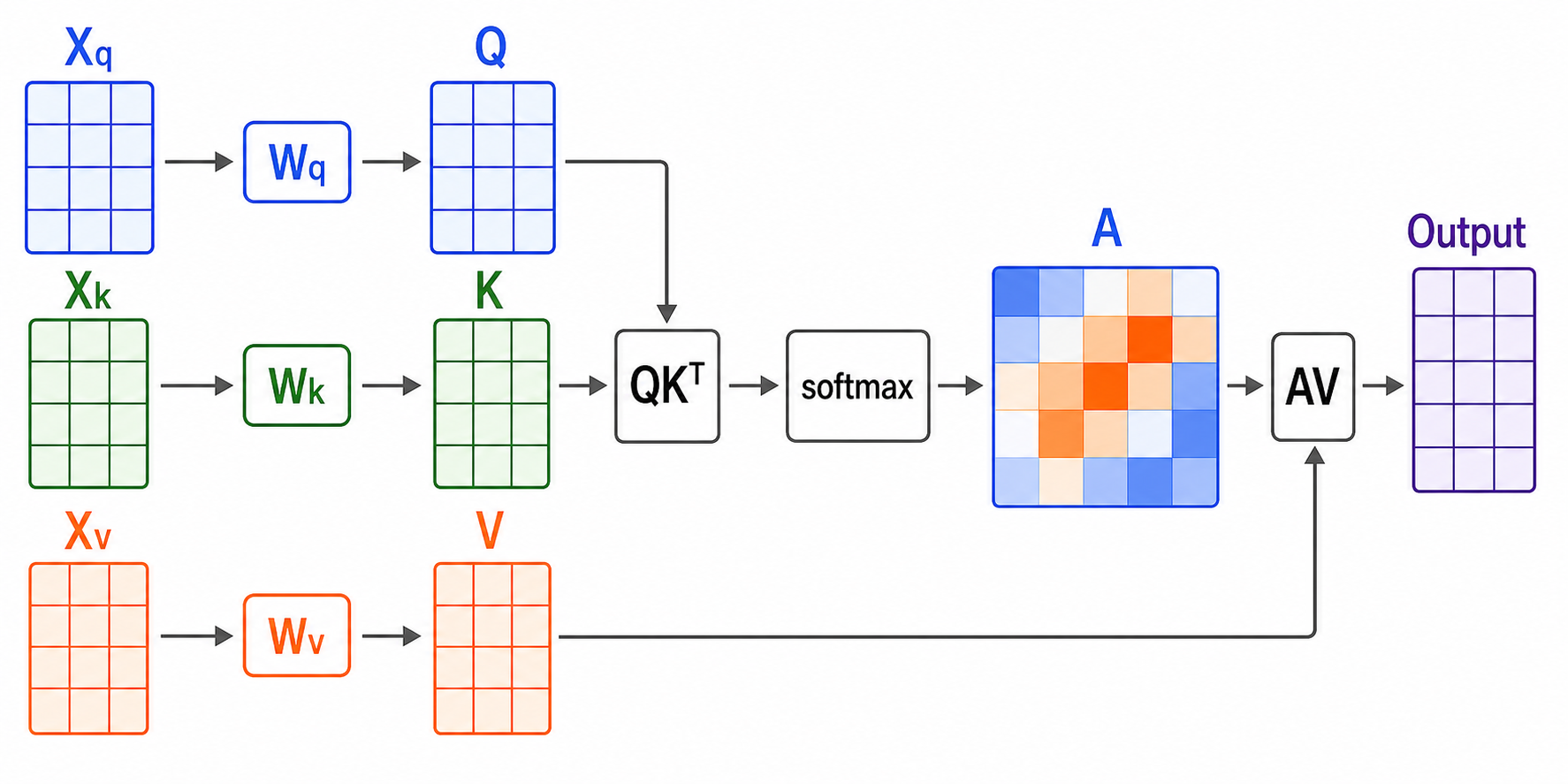
図 9.6 注意機構のイメージ図#
注意機構は、通常、クエリ (query)、キー (key)、バリュー (value) の3つのベクトル (ここでは \(\mathbf{X}_q\)、\(\mathbf{X}_k\)、\(\mathbf{X}_v\) とする)を入力として受け取る。
これらの特徴量を異なる全結合層で線形変換して \(\mathbf{q} = \mathbf{W}_\text{q} \mathbf{X}_q\)、\(\mathbf{k} = \mathbf{W}_\text{k} \mathbf{X}_k\)、\(\mathbf{v} = \mathbf{W}_\text{v} \mathbf{X}_v\) という3つの特徴ベクトルを得る。
その後 \(\mathbf{q}\) と \(\mathbf{k}\) の内積を計算し、 \(\mathbf{v}\) 中のどの要素に注目すべきかを表す注意重み (attention weights) を要素とする行列 \(\mathbf{A}\) を得る。
ただし、この式で \(d_k\) は \(\mathbf{k}\) の次元数である。
この行列を \(\mathbf{v}\) に掛けた後、更に全結合層で線形変換することで、注意機構の出力を得る。また、Transformerに用いられる注意機構はしばしば残差接続を持ち、出力ベクトル \(\mathbf{y}\) は、次のように計算されることが多い。
注意機構は、入力のバリューベクトル全体に広い受容野を持ち、それでいて、畳み込み層や全結合層で入力全体を受容野とするよりも、少ないパラメータで表現できるという特徴がある。
また、Transformerでは、複数の注意機構を並列に計算する マルチヘッド注意機構 (multi-head attention) を用いることが多い。ここでは詳細を述べることはしないが、複数の注意機構を利用することで、異なる特徴に対して異なる注意を払うようになる。
自己注意機構と交差注意機構#
Transformerでは注意機構に対して、入力のクエリ、キー、バリューに同一の特徴量を与える *自己注意機構 (self-attention) と、キー・バリューだけを同一にし、クエリを別の入力から得る 交差注意機構 (cross-attention) の2種類が用いられる。
自己注意機構は、入力の特徴量同士が互いにどのような関係にあるかを学習するために用いられる。例えば、自然言語処理の文脈では、ある単語が文中の他の単語とどのような関係にあるかを学習するために自己注意機構が用いられる。
一方で、交差注意機構は、エンコーダとデコーダの間で情報をやり取りするために用いられる。例えば、機械翻訳の文脈では、エンコーダが入力言語の特徴量を生成し、デコーダが出力言語の特徴量を生成する際に、エンコーダの出力をキー・バリューとして利用し、デコーダのクエリと照合することで、翻訳に必要な情報を引き出すために交差注意機構が用いられる。
位置エンコーディング#
Transformerが順序を持つ系列データを処理するためには、入力の各要素の位置を表す情報をモデルに与える方が良い。
この役割を担うのが 位置エンコーディング (positional encoding) という仕組みである。Transformerで広く用いられている位置エンコーディングでは、入力の各要素に対して、特定の多次元ベクトルを加算する。
一例として、Transformerの元論文では、次のような三角関数に基づく位置エンコーディングが提案されている。
ここで、\(p\) は入力の位置を表す整数、\(i\) は位置エンコーディングの次元数を表す整数、\(d_\text{model}\) はTransformerのモデルの次元数である。このベクトルは、およそランダムに近い値を持ちながらも、ある程度、位置の変化に対する連続性も持つように設計されている。
9.5.2. ViT#
9.5.3. ViTの基本構造#
ViTの基本的な考え方は、画像をパッチの系列として表現し、その系列に対してTransformer encoderを適用することである。通常のTransformerは単語やサブワードなどのトークン系列を入力とするが、ViTでは画像を固定サイズのパッチに分割し、各パッチを1つのトークンのように扱う。
入力画像を \(\mathbf{x}\in\mathbb{R}^{H\times W\times C}\)、パッチサイズを \(P\times P\) とすると、パッチ数は
となる。各パッチを平坦化すると、1つのパッチは \(P^2C\) 次元のベクトルとして表される。これを学習可能な線形変換によって \(D\) 次元のベクトルへ写像したものを、パッチ埋め込みと呼ぶ。
また、ViTでは系列の先頭に分類用の特別なトークンを追加する。このトークンは、Transformer encoderを通じて各パッチの情報を集約し、最終的に画像全体を表す特徴量として用いられる。さらに、自己注意機構だけではパッチの位置情報を区別できないため、各パッチ埋め込みには位置エンコーディングを加える。
ViTの特徴は、畳み込み層を用いず、パッチ間の関係を自己注意機構によって直接学習する点にある。CNNでは局所性や平行移動同変性がモデル構造に組み込まれているが、ViTではそのような画像特有の帰納バイアスは弱い。そのため、小規模なデータではCNNに比べて不利になることがある一方で、大規模データで事前学習すると高い性能を発揮する。
ViTを画像分類に利用する場合、Transformerのエンコーダに入力される系列は、クラス・トークンと呼ばれる特殊なトークンと、画像をパッチに分割して得られるパッチ・トークンの組み合わせで構成される。Transformerエンコーダの出力のうち、クラス・トークンに対応するベクトルが、画像全体を表す特徴量として利用され、これを全結合層などで変換して、最終的なクラス分類の出力を得る。
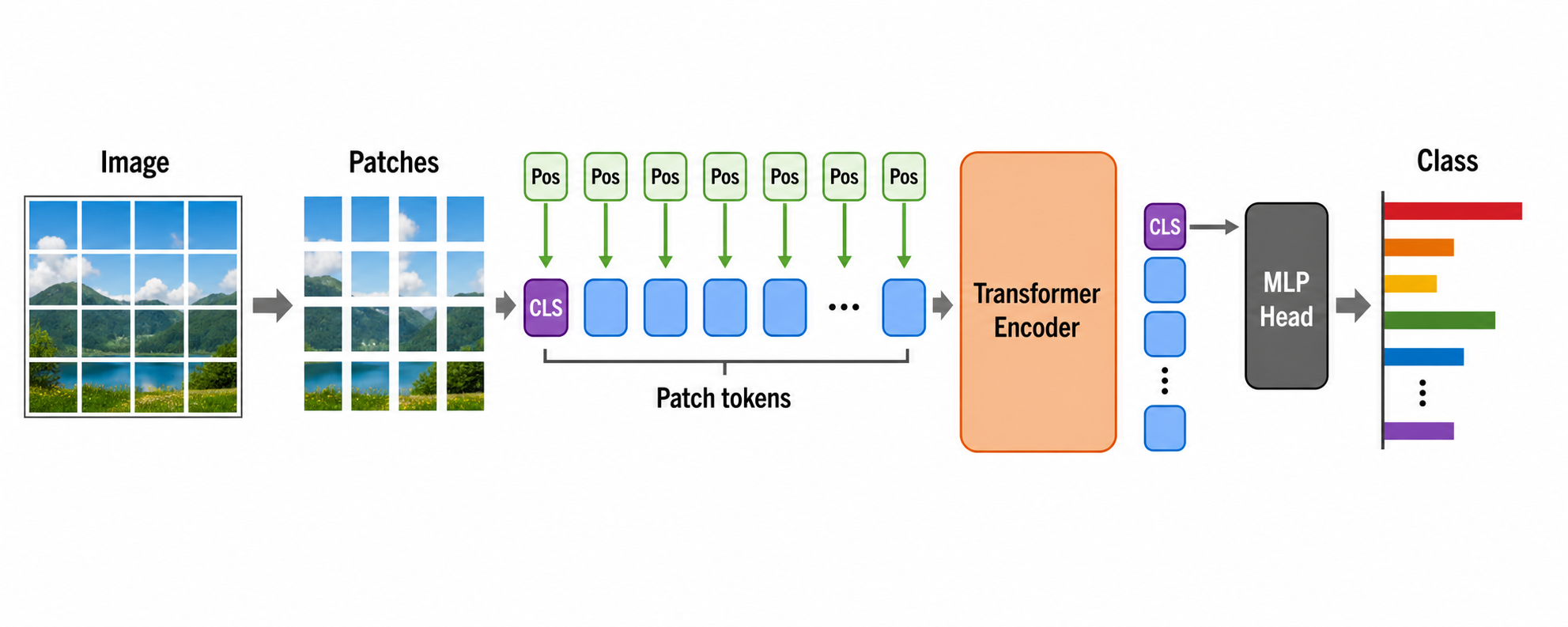
図 9.7 ViTを用いた画像分類のイメージ図#
ただ、一般の応用ではViTが画像の構造を学習するに足る量のデータを集められないこともあるため、学習済みのCNNを教師として、その教師CNNの判断がTransformerデコーダの出力の一部として学習されるようにする (このような出力の模倣による学習を 知識蒸留 (distrillation) と呼ぶ) ことで、少ない訓練データからでもViTを学習する手法 (DeiT, data-efficient image transformers) なども提案されている。 [39]。
まとめ: 深層学習と画像認識
画像認識における深層学習モデルはLeNet-5を始めとして、畳み込みニューラルネットが主流となってきた
AlexNet以降、徐々にニューラルネットの層の数を増やすことで認識精度を高めてきた
今日では、Vision Transformer (ViT)のように、CNN以外のニューラルネットにも注目が集まっている
9.6. プログラミング演習#
レポートは テンプレートファイル を使用して作成してください。また、ファイル名は 「(7桁の学籍番号)_第x回_画像処理レポート.docx」 (xの部分は何回目の課題なのかを記入)に変更してください。
課題作成上の注意
課題を作成する際には、プログラムは別に .py ファイルで作成して、本レポートと一緒に圧縮したうえで提出してください。また、Jupyter Notebook形式のファイル (拡張子が.ipynb)のものは受け付けません。
加えて、プログラムを添付したのみで内容に関する説明や結果に関する考察のないもの、単なる結果の羅列になっているもの(またはそのように見えるもの)は採点しませんのでご注意ください。
CNNの構造とその影響
以下のURLにあるGoogle Colabのノートブック上でCNNの構造を変化させた時に、分類の精度や学習の速度がどのように変化するかを確認せよ。
特に、バッチ正規化やドロップアウトの有無、畳み込み層の数、カーネルサイズなどが与える影響について、実験結果を踏まえて考察せよ。
注意: ノートブック中の model = ConvNet() と書かれている部分をコメントから外すこと。
ViTの構造とその影響
以下のURLにあるGoogle Colabのノートブック上でViTの構造を変化させた時に、分類の精度や学習の速度がどのように変化するかを確認せよ。
特に、パッチのサイズ、Transformer層の数、ヘッド数などが与える影響について、実験結果を踏まえて考察せよ。
注意: ノートブック中の model = SimpleVit() と書かれている部分をコメントから外すこと。