3. 演習: 物体検出/画像特徴量#
3.1. はじめに#
レポートは テンプレートファイル を使用して作成してください。また、ファイル名は 「(7桁の学籍番号)_第x回_画像処理レポート.docx」 (xの部分は何回目の課題なのかを記入)に変更してください。
課題作成上の注意
課題を作成する際には、プログラムは別に .py ファイルで作成して、本レポートと一緒に圧縮したうえで提出してください。また、Jupyter Notebook形式のファイル (拡張子が.ipynb)のものは受け付けません。
加えて、プログラムを添付したのみで内容に関する説明や結果に関する考察のないもの、単なる結果の羅列になっているもの(またはそのように見えるもの)は採点しませんのでご注意ください。
3.1.1. OpenCVを用いたテンプレート・マッチング#
Pythonで愚直にテンプレート・マッチングを実装する場合、画像と画像の類似度計算に多大な時間がかかることになり、あまり現実的ではない。
以下では、裏側ではC++を用いて実装されているOpenCVを用いて、テンプレート・マッチングを試してみよう。本演習でも、次の数独の画像を用いる。
図 3.1 本演習で用いる数独の画像#
|
|
|
|
|
|
|
|
|









OpenCVを用いたテンプレート・マッチングには cv2.matchTemplate を用いる (参考)。
この関数は、入力画像が (H, W) のサイズ、テンプレートが (h, w) のサイズのとき、出力画像は (H-h+1, W-w+1) のサイズになる。そこで、以下の参考コードでは、 cv2.matchTemplate から出力される画像のサイズを入力画像と同じにするために、入力画像の周囲に np.pad を使って縁をつけている。
cv2.matchTemplate は、第1, 第2引数にそれぞれ入力画像とテンプレート画像を取り、第3引数にはマッチングの手法を取る。本資料で紹介した手法のうち、SDD, NCC, ZNCCの3つは、
SDD:
cv2.TM_SQDIFFNCC:
cv2.TM_CCORR_NORMEDZNCC:
cv2.TM_CCOEFF_NORMED
にそれぞれ対応している。
適当な閾値を用いて、テンプレートがマッチする箇所を検出したら、OpenCVの cv2.rectangle を用いて、検出箇所にテンプレートと同サイズの矩形を描画している。
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 画像の読み込み
img = cv2.imread("data/sudoku_rectified.png", cv2.IMREAD_GRAYSCALE)
tmp = cv2.imread("data/digit_2.png", cv2.IMREAD_GRAYSCALE)
H, W = img.shape[:2]
h, w = tmp.shape[:2]
print(f"Size (input): {W:d}x{H:d}")
print(f"Size (template): {w:d}x{h:d}")
# 入力画像の周囲に縁をつけてマッチング結果が
# 入力画像と同サイズになるようにする
pad_l = w // 2
pad_r = w - pad_l - 1
pad_t = h // 2
pad_b = h - pad_t - 1
img = np.pad(img, ((pad_t, pad_b), (pad_l, pad_r)), mode="constant", constant_values=255)
# マッチング (ZNCC)
match = cv2.matchTemplate(img, tmp, cv2.TM_CCOEFF_NORMED)
# しきい値以上の画素を検出する
threshold = 0.95
pixels = np.where(match >= threshold)
# マッチした画素の周囲にテンプレートと
# 同じサイズの矩形を描画する
result = cv2.cvtColor(img, cv2.COLOR_GRAY2RGB)
for y, x in zip(*pixels):
cv2.rectangle(result, (x, y), (x + w, y + h), (255, 0, 0), 1, cv2.LINE_AA)
# 結果の表示
fig, ax = plt.subplots()
ax.imshow(result)
ax.axis(False)
plt.show()
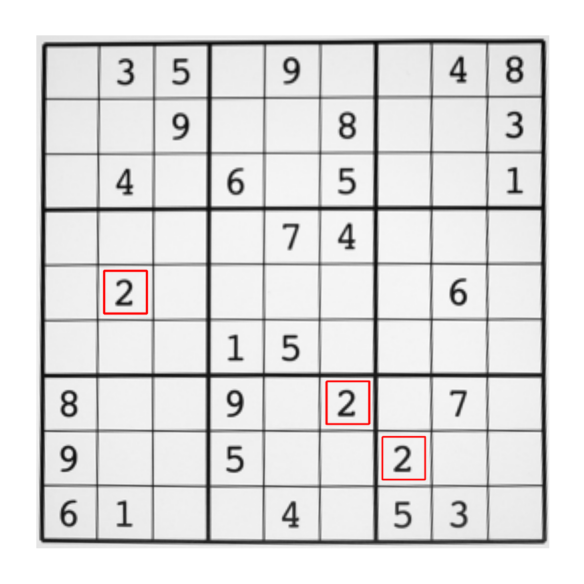
図 3.2 OpenCVによるテンプレート・マッチングの結果#
3.1.2. BoVWを用いた画像認識#
以下の演習では、 Oxford-IIIT Pet Dataset から抽出した犬の画像100枚と猫の画像100枚を用いて、BoVWによる画像分類のプログラムを作成する。
まず、上のリンクから oxforad_pet_200.tar.gz をダウンロードする。ダウンロード後、ファイルを展開し oxforad_pet_200 というフォルダの中に annotations.csv というファイルと images というフォルダがあることを確認する。
images には犬と猫の画像がそれぞれ200枚ずつ格納されていて、annotations.csv には、それぞれの画像に対するラベルが付与されている。各画像は長辺の長さが500pxになるようにサイズ調整されている。
annotations.csv には ID, SPECIES, BREED ID という3つの列があり、この中で SPECIES が1ならば猫、2ならば犬を表している。
データの読み取り#
oxforad_pet_200 のフォルダ内にある annotations.csv は、第1列に猫や犬の種類を含む画像の名前が入っており、3列目に猫か犬かを表すラベルが含まれている。
まずはCSVファイルをpandasの read_csv を用いて読み込み、 DataFrame の query メソッドを用いて猫の画像と犬の画像を1枚ずつ取り出してみる。
import pandas as pd
# アノテーションの読み込み
anno_file = "oxford_pet_200/annotations.csv"
data = pd.read_csv(anno_file, index_col=0)
# 猫の画像だけ取り出す
cats = data.query("SPECIES == 1")
# 犬の画像だけ取り出す
dogs = data.query("SPECIES == 2")
# 猫の1枚目の画像名
cat_name_0 = cats.index[0] + ".jpg"
# 犬の1枚目の画像名
dog_name_0 = dogs.index[0] + ".jpg"
# 画像を読み込む
cat_img_0 = cv2.imread(f"oxford_pet_200/images/{cat_name_0}", cv2.IMREAD_COLOR)
dog_img_0 = cv2.imread(f"oxford_pet_200/images/{dog_name_0}", cv2.IMREAD_COLOR)
# BGRからRGBに変換 (表示用)
cat_img_0 = cv2.cvtColor(cat_img_0, cv2.COLOR_BGR2RGB)
dog_img_0 = cv2.cvtColor(dog_img_0, cv2.COLOR_BGR2RGB)
# 表示
fig = plt.figure()
ax = fig.add_subplot(121)
ax.imshow(cat_img_0)
ax.axis(False)
ax.set_title(cat_name_0)
ax = fig.add_subplot(122)
ax.imshow(dog_img_0)
ax.axis(False)
ax.set_title(dog_name_0)
fig.tight_layout()
plt.show()
このように、各画像の名前は data.index[i] のような形で取得できるので、 i を画像のインデックスとしてデータを走査することで、全ての画像名を取得することができる。

図 3.3 猫と犬の画像の例#
SIFT特徴量の抽出#
OpenCVを用いたSIFT特徴量の抽出には cv2.SIFT.create を用いて作成される特徴抽出器を用いる。
特徴抽出器には、特徴点を抽出する detect メソッドと、特徴点に対して特徴量を計算する compute メソッドがあるが、これらを同時に実行する detectAndCompute メソッドを用いるのが便利だろう。
抽出された特徴量はNumPyの配列として返されるので、あとの処理で用いるために *.npy 形式で保存しておくと、何度も特徴点の抽出を行う手間が省ける。
import os
import cv2
import numpy as np
# 特徴量抽出器の作成
sift = cv2.SIFT.create()
# 画像の読み込み
img_name = cats.index[0] + ".jpg"
cat_img = cv2.imread(f"oxford_pet_200/images/{img_name}", cv2.IMREAD_COLOR)
# 特徴点と特徴量の検出
kpts, desc = sift.detectAndCompute(cat_img, np.empty(0))
# 保存先のディレクトリを作成
os.makedirs("oxford_pet_200/features", exist_ok=True)
# 特徴量を保存
npy_name = cats.index[0] + ".npy"
np.save(f"oxford_pet_200/features/{npy_name}", desc)
なお、抽出された特徴点と対応する特徴量は cv2.drawKeypoints を用いて描画することができる。
# 特徴点を画像上に描画
cat_img_kpts = cv2.drawKeypoints(
cat_img,
kpts,
np.empty(0),
flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS,
)
# 画像の表示
fig, ax = plt.subplots()
ax.imshow(cat_img_kpts[..., ::-1])
ax.axis(False)
plt.show()

図 3.4 SIFT特徴量の可視化結果#
特徴量のクラスタリング#
全ての画像から特徴量の抽出が完了したら、訓練データの画像の特徴量を全て読み込み、それらをクラスタリングすることでコードブックを作成する。
特徴量を先ほどまでの処理で保存しておいた *.npy ファイルから読み取るとすると、ソースコードは次のようになるだろう。
features = []
for i in train_idx:
# 特徴量を読み込み
name = data.index[i]
npy_name = name + ".npy"
desc = np.load(f"oxford_pet_200/features/{npy_name}")
# 特徴量の数を取得
n_desc = desc.shape[0]
# 特徴量の数を保存
features.append(desc)
features = np.concatenate(features, axis=0)
こうして features に全ての特徴量を格納すると、SIFT特徴量の次元が128次元であることから、総特徴点数を N として features のサイズは (N, 128) となる。
この形のNumPyの配列をk平均法によりクラスタリングするには、scikit-learnの sklearn.cluster.KMeans を用いるのが良い。なお、OpenCVにもk平均法の実装として cv2.kmeans が提供されているが、最近傍クラスタのインデックス計算などの処理がscikit-learnを用いるほうが容易である。
# k平均法によるクラスタリング
kmeans = KMeans(n_clusters=n_clusters, max_iter=100)
kmeans.fit(features)
クラスタリングが完了すると、kmeans.cluster_centers_ にクラスタの中心情報が格納される。ただし、この中心に対して直接距離を計算して最近傍のクラスタ中心を求める必要はなく、kmeans.predict メソッドを用いると、各特徴量の最近傍クラスタ中心のインデックスを取得することができる。
さらに最近傍クラスタのインデックス情報を含む配列から、各インデックスの出現頻度を計算するには、NumPyの np.bincount を用いるのが便利である。以上をまとめると、各画像からBoVWの特徴量を計算するソースコードは次のようになる。
# 特徴量を読み込み
name = data.index[i]
npy_name = name + ".npy"
desc = np.load(f"oxford_pet_200/features/{npy_name}")
# 特徴量のヒストグラム化
pred = kmeans.predict(desc)
feat = np.bincount(pred, minlength=n_clusters)
feat = feat / np.sum(feat)
分類器の学習と混合行列による評価#
以上の処理を全ての画像に対して行って、全訓練画像を特徴ベクトル化できたら、これらのベクトルと各画像のラベルを組み合わせて分類器を訓練する。
今回の演習では分類器にscikit-learnの sklearn.svm.SVC で提供されるサポート・ベクトルマシンによる分類を用いる。 SVC にはいくつかのパラメータがあるが、今回は特にパラメータを変更せずに用いる。
分類器が訓練できたら、まずは訓練データに対する分類器の精度を評価し、訓練が正常におこなえているかを確認する。混合行列の計算にはscikit-learnの sklearn.metrics.confusion_matrix を用いれば良い。
以上の処理をまとめると、以下のようなソースコードになるだろう。
# 分類器の学習
clf = SVC()
clf.fit(X_train, y_train)
# 混同行列の準備
mtx = confusion_matrix(y_train, clf.predict(X_train))
disp = ConfusionMatrixDisplay(mtx, display_labels=["cat", "dog"])
# 表示
fig, ax = plt.subplots()
disp.plot(ax=ax, cmap="Blues", colorbar=False)
ax.grid(False)
fig.tight_layout()
plt.show()
まとめコード#
ここまでに紹介した各工程を全てまとめたものが以下のコードである。これを参考にして、以下の演習に取り組んでみてほしい。
import cv2
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.cluster import KMeans
from sklearn.metrics import ConfusionMatrixDisplay, confusion_matrix
from sklearn.model_selection import train_test_split
# パラメータ
anno_file = "oxford_pet_200/annotations.csv"
feat_dir = "oxford_pet_200/features"
n_clusters = 32
# 特徴量抽出器の作成
sift = cv2.SIFT.create()
# データの読み取り
data = pd.read_csv(anno_file, index_col=0)
# データの分割
indices = np.arange(len(data))
train_idx, test_idx = train_test_split(indices)
# 特徴量保存先のディレクトリを作成
os.makedirs(feat_dir, exist_ok=True)
# 画像から特徴量を抽出 (train/test)
print("Step 1: Feature extraction")
for i in indices:
# 画像の読み込み
name = data.index[i]
img_name = name + ".jpg"
img = cv2.imread(f"oxford_pet_200/images/{img_name}", cv2.IMREAD_COLOR)
# 特徴点と特徴量の検出
_, desc = sift.detectAndCompute(img, np.empty(0))
# 特徴量を保存
npy_name = name + ".npy"
np.save(f"oxford_pet_200/features/{npy_name}", desc)
# コードブックの作成 (trainのみ)
print("Step 2: Clustering")
features = []
for i in train_idx:
# 特徴量を読み込み
name = data.index[i]
npy_name = name + ".npy"
desc = np.load(f"oxford_pet_200/features/{npy_name}")
# 特徴量の数を保存
features.append(desc)
features = np.concatenate(features, axis=0)
print(f"Total features: {features.shape[0]:d}")
# クラスタリング
kmeans = KMeans(n_clusters=n_clusters, max_iter=100)
kmeans.fit(features)
print("Clustering OK")
# 画像の特徴ベクトル化 (trainのみ)
print("Step 3: Vectorize images")
X_train = []
for i in train_idx:
# 特徴量を読み込み
name = data.index[i]
npy_name = name + ".npy"
desc = np.load(f"oxford_pet_200/features/{npy_name}")
# 特徴量のヒストグラム化
pred = kmeans.predict(desc)
feat = np.bincount(pred, minlength=n_clusters)
feat = feat / np.sum(feat)
X_train.append(feat)
X_train = np.array(X_train, dtype=np.float32)
y_train = np.array(data.SPECIES.iloc[train_idx], dtype=np.int32)
# 分類器の訓練
print("Step 4: Train classifier (SVM)")
clf = SVC()
clf.fit(X_train, y_train)
print("SVM is trained")
# 混同行列の準備
mtx = confusion_matrix(y_train, clf.predict(X_train))
disp = ConfusionMatrixDisplay(mtx, display_labels=["cat", "dog"])
# 表示
fig, ax = plt.subplots()
disp.plot(ax=ax, cmap="Blues", colorbar=False)
ax.grid(False)
fig.tight_layout()
plt.show()
3.2. 演習問題#
テンプレート・マッチングによる数字の検出
前述のOpenCVを用いたテンプレート・マッチングのコードに倣い、数独の画像に対して1から9までの数字を検出し、異なる色の矩形で囲んで表示せよ。
BoVWによる画像認識 (1)
前述のまとめコードに倣い、自身でBoVWによる画像識別を試してみよ。その後、プログラムを改変し、テスト画像 (インデックスは test_idx) に対しての識別精度を評価せよ (まとめコードでは訓練画像に対して精度を評価している)。
BoVWによる画像認識 (2)
前述のまとめコードではSIFTを特徴抽出器として用いたが、OpenCVには資料でも紹介したORBの他にKAZE [52] やBRISK [53] といった特徴抽出器が実装されている (参考)。SIFTの代わりに別の特徴抽出器を用いるとBoVWによる画像分類の精度がどう変化するか調査せよ。
BoVWによる画像認識 (3)
コードブックの作成にk平均法の代わりに混合Gauss分布を用いるプログラムを作成し、分類精度に与える影響について調査せよ。混合Gauss分布はscikit-learnの sklearn.mixture.GaussianMixture を用いれば良く、各特徴点が持つ特徴点が各Guass分布に従う確率は predict_proba を用いれば良く、画像全体の特徴は、predict_proba により得られる確率ベクトルを全特徴点について平均すれば良い。