1. デジタル画像#
現在、写真といえばデジタル画像のことであり、多くは画素の色情報がデジタル、つまり二進数によって表される数字として記録されている。しかし、従来、写真とは現実世界の光の強さの情報をデジタルデータやフィルム上に記録したものである。
本節では、代表的なデジタル画像の形式であるラスタ形式の画像のについて、その表現方法と表示方法について紹介した後、デジタル画像の取得方法の一つでもあるカメラの仕組みついて紹介する。
クイズ1
あなたは画像データを機械学習のモデルに入力するための前処理を行っている。あなたが目視で確認したところ、前処理の前後で画像の見た目は変わっていないようだ。
しかし、前処理をする前の元画像を機械学習した場合と、前処理後の画像を機械学習した場合で、モデルの性能が大きく異なってしまった。これはなぜだろうか?
クイズ2
あなたは、所属するクラブのイベント準備のために案内用の看板を作成している。ノートPCの画面で見たときには、看板に書かれた文字はとても鮮明に見えたが、実際に印刷してみると、少し文字がぼやけてしまった。これはなぜだろうか?
参考資料
『ディジタル画像処理 改訂第二版』 P.15 第2章 ディジタル画像の撮影
1.1. デジタル画像の表現#
画像という言葉は「画く (えがく)」ことによって得られた「像 (ぞう)」という意味である。いわゆるデジタル画像が普及する前にはそれほど一般的に使われる言葉ではなく、写真ならば写真、絵画ならば絵画、というように画像の表現方法によって異なる呼び方をしていた。
その後、パーソナルコンピュータが普及するに従って、デジタルデータとしての写真やイラストを編集・作成できるようになると、デジタルデータとしての写真やイラストの総称として「画像」という言葉が広く用いられるようになった。
現在、デジタル画像の表現には大きく分けて、ラスタ形式 (raster format)とベクタ形式 (vector format)があるが、意図せずデジタル画像という言葉が使われているときには、ラスタ形式の画像を指すことが多い。
ラスタ形式は、画素を格子状に並べ、各画素に色を割り振ることで画像が表現される。また、ラスタ形式の画像のことを ビットマップ (bitmap) と呼ぶこともある。ラスタ形式の画像には、解像度が存在し、画質が解像度によって制限されるが、表現の柔軟性に優れている。
次の猫の画像は、縦300画素、横450画素の13万5000画素で表現されている。

各画素には色情報として (104, 120, 143) ような3つ組の値が記録されている。通常、この三つの値は0から255の間の整数、すなわち 8ビット符号なし整数 によって表される。
色の表現については次節「 カラー画像と色空間 」で詳しく述べるが、世の中で広く用いられているJPEGやPNGなどの画像形式では、三つの整数は、赤、緑、青の三成分に対応している。
注意
ラスタ形式で表現されたデジタル画像をビットマップ画像と呼ぶこともあるが、画像のファイル形式の.bmpとは微妙に異なるので注意。
1.1.1. 画素による標本化#
現在、画素の集合で表されるデジタル画像は深く日常生活に浸透しているため、ここまでの説明において、「画像 = 画素の集まり」という説明に違和感を覚える読者は少ないのではないかと思う。
しかし、よく考えてみると、我々の生活している世界は 画素のような離散化された世界ではない 。ここで「画素」と呼んでいるものは小さな矩形領域で、その内部が特定の色で塗りつぶされている。しかし、画素がどんなに小さな領域を覆う矩形であったとしても、現実世界では、その矩形領域内部は「一色」だけでは表現できない。
今日、市販のスマートフォンやデジタルカメラで撮影できる画像は縦横に数千の画素が並んでいるが、もし画像の解像度が低く数百あるいは数十程度しか画素がなければ、この事実は容易に理解できるだろう。

以上を踏まえると、ラスタ画像は 現実世界にある連続的な信号を格子状に並んだ点でサンプリングしたもの であると見なせる。このように連続的な対象を離散的な点の集合によって表現することを 標本化 (sampling) と呼ぶ。
1.1.2. 色情報の量子化#
現実世界の色、というのは 波長の異なる光が人間の脳内で処理された結果 であると考えることができる。人間の持つ視細胞は主に赤、緑、青に対応する波長に強く反応するため、多くのデジタル画像表現では、色の表現に赤、緑、青の3成分を表す数値の組を用いる。
では、人間の脳で、赤色に対応する波長の光が処理される時に、その反応の強さは0-255のような離散的な値なのか、といえば、当然ながらそうではない。
従って、デジタル画像において、赤、緑、青の各成分が0-255の8ビット符号なし整数で表されているというのは、あくまで形式的なものに過ぎず、色に対応する光の強さは、「光の強さレベル」で離散化されている。
このように、アナログ信号として得られる光強度の実数値を、解像度が有限なデジタル値に置き換える処理を 量子化 と呼ぶ。
色を表す光の強度は物理的には放射照度 \(E\) (単位: \(\mathrm{[W/m^2]}\))に対応しており、この強度は正の実数全体で値を取りうる。
ただし、現実的には、光の強度は特定の範囲に \(E_{\text{min}}\) から \(E_{\text{max}}\) の範囲に収まっていると考えられるため、
のように、値が0から1の範囲に収まるように正規化する。量子化に用いるビット数を \(B\) とすると、この \(E'\) に \(2^B\) を乗じて整数に直すことで、最終的な画素値が得られる。
この際、とある画素に101のような値が保存されているとして、これが101から102の間の実数値でどれに対応するのかを知ることはできず、0から1の範囲で考えたときに、最大 \(2^{-B}\) の誤差が生じる。この誤差を 量子化誤差 と呼ぶ。より多くのビットを用いると量子化誤差は小さくなるため、元の信号をより忠実に表せるようになる。
通常、1画素あたりのデータ量は赤、緑、青の各成分に8ビットずつの合計24ビットである。1画素を表すのに用いられるビット数のことを特にビット深度と呼び、一般的なカラー画像は24ビット深度を持つ。
PNG形式などの一部のラスタ画像形式はさらに8ビットで画素の透明度を表すような32ビット深度の形式も表せる他、デジタル一眼レフのような高価なカメラではRAW画像と呼ばれるビット深度の大きな画像を得ることもできる。
ラスタ画像
ラスタ画像は画素の集合で表現されるデジタル画像であり、カラー画像の場合、通常、各画素には赤、緑、青の三成分を表す整数が記録されている。
「画素」は連続的な実世界を離散的な点の集合でサンプリングしたものであり、このような離散点による表現への変換を標本化と呼ぶ。
画素に記録された色情報はアナログな光強度をデジタル値である整数値で表現し直したもので、この操作を量子化と呼ぶ。
1.1.3. ラスタ画像の圧縮#
ここまで、多くのラスタ画像形式は赤、緑、青の3色を各8ビットで表現していることを述べた。従って、1画素あたりのデータ量は24ビット、すなわち3バイトである。これを300×450画素の画像に当てはめると、405000バイト、すなわち約405キロバイトのデータ量が必要となる。
では、前述の猫の画像を実際に各自のコンピュータにダウンロードして、そのデータサイズを確認してみてほしい。一体、どのくらいのデータ量になっているだろうか?
画像をダウンロードすると、ファイルはPNG (portable network graphics)形式で保存されている。おそらく画像のサイズは223キロバイト程度になっているはずで、これは実際に画像を表すのに必要な405キロバイトよりもかなり小さくなっている。
また、画像を別のファイル形式であるJPEG (Joint Photographic Experts Group)形式で保存すると、さらに画像が小さくなるはずだ。ウェブ上にはPNG形式の画像をJPEG形式の画像に変換するためのツールがあるので、それらを使ってファイルサイズを確かめてみよう。
練習問題
検索エンジンで「PNG to JPEG converter」などと検索して表示されるウェブサイトを使って、PNG形式の画像をJPEG形式の画像に変換せよ。その際、変換後の画像のデータサイズが何キロバイトになるかを確かめよ。
JPEG形式の画像がどの程度のデータサイズになるかは、圧縮の度合いによって異なるが、概ね数十キロバイト程度までデータサイズを圧縮できているのではないだろうか。
画像のデータは一般にサイズが大きく、多数の画像を限られたストレージに保存するには、データ圧縮されることが望ましい。画像の圧縮方式には 不可逆圧縮 (lossy compression) と 可逆圧縮 (lossless compression) の2種類がある。
例えば、前述のJPEG形式は不可逆圧縮であり、一度圧縮してしまうと、圧縮前の元画像を復元することはできない。一方、PNG形式は可逆圧縮であり、データサイズを削減しながら、元の画像を完全に復元することができる。一般に、可逆圧縮よりも不可逆圧縮の方が高い圧縮率を得ることができ、写真のような自然画像を圧縮する場合には、その品質を損なうことも少ない。
JPEG形式#
JPEG形式の画像圧縮には、離散コサイン変換が用いられる。離散コサイン変換は、特定の信号を余弦関数の重ね合わせによって表現する手法であり、画像にどの程度の周波数の信号が含まれているかを調べることができる。
人間の視覚は、特定の周波数の成分が大きくなったり小さくなったりしたとしても、画像の変化に気づきづらいという特性がある。そこで、JPEG形式の画像圧縮では、画像を8×8のブロックに分割した後、各ブロックごとに離散コサイン変換を行って、画像を周波数成分の情報に変換する。
その後、周波数成分の情報をハフマン符号とランレングス符号化によって更に圧縮する。この際、特定の周波数成分の情報が量子化によって部分的に失われるため、JPEG形式は不可逆圧縮である。
実際、JPEG形式で画像を圧縮すると、圧縮率に応じて、 ブロックノイズ や モスキートノイズ と呼ばれる画像の劣化 (専門的にはアーティファクト (artifact)と呼ぶ)が生じる。

図 1.1 JPEG圧縮された画像とモスキートノイズ、ならびにブロックノイズの例#
詳細なJPEG圧縮のアルゴリズムについて本項で述べることはしないが、興味のある読者は拙書の講義資料 JPEG圧縮の概要 や [1] を参照されたい。
PNG形式#
PNG形式の画像圧縮にはLZ77符号化と呼ばれるアルゴリズムとハフマン符号を組み合わせた Deflate と呼ばれる手法が用いられている。Deflateは一般的なファイル圧縮方法であるZIP形式にも用いられている。ZIP形式は圧縮されたデータを損なってしまってはいけないため、Deflateが可逆圧縮であることは容易に想像できる。
Deflateで用いられるLZ77符号化には、スライド辞書と呼ばれる動的な辞書が用いられる。このスライド辞書は先頭から順にデータを見ていく際に、一定範囲の直近の内容を辞書として用いる。データを走査中に、辞書内に含まれるデータ列が見つかった場合には、辞書上の位置と一致するデータ長を記録することでデータを圧縮する。
PNG形式の画像圧縮は画素を縦方向、あるいは横方向の走査線ごとに圧縮する。ただし、走査線上に並ぶ画素値は必ずしもLZ77符号化で上手く圧縮できるような繰り返しを含むものばかりではないので、各走査線に対して、隣接する画素との平均や差分を取るなどの前処理 (フィルタリング)を施し、より高い圧縮率が得られるように工夫している。
練習問題
画像圧縮には、文中で紹介したJPEG形式やPNG形式の他にも、GIF形式やWebP形式などの多数の圧縮アルゴリズムが用いられる。これらの圧縮アルゴリズムを以下の観点で比較し、各アルゴリズムがどのような応用に適しているかを考察せよ。
可逆圧縮か不可逆圧縮か
圧縮率
圧縮と展開の速度
透明度の扱い
扱えるビット深度
ベクタ画像
ベクタ画像は、イラストのような線や特定の色で塗りつぶされた図形の組み合わせで画像を表現した画像形式である。
図形は数式のような形で表現されているため、画像を拡大・縮小したとしても、その拡大率に応じた画像を数式から計算し直すことで、常にボケのない鮮明な画像を得ることができる。例えば、文字を表すフォントなどはベクタ形式で表現されているため、Wordなどのソフトで文字を拡大しても、ラスタ画像のようにジャギーが発生することはない。
ここで「数式」と呼んでいるものは、2点を通る直線の式や、とある点を中心とする円の他、曲線を表す多項式などが含まれ、代表的なものにはBézier曲線などがある。
1.2. デジタル画像の表示#
デジタル画像が実際にどのようなものかを確認するには、ディスプレイやプロジェクタ等による表示が必要である。ここでは、ディスプレイを用いたデジタル画像の表示方法について簡単に紹介する。
1.2.1. ディスプレイの基本原理#
ディスプレイには現在は入手することが困難なものも含めていくつもの種類がある。最初期のディスプレイは ベクタスキャン型 と呼ばれる形式で、特定の座標の間の線を描画することで画像を表示していた。
これに対して、現在、一般的に用いられているディスプレイは ラスタスキャン型 と呼ばれる形式で、画面全体を縦横に格子状に分割した画素の集合を用いて画像を表示する。ラスタスキャン型では、画素の表示が横方向 (あるいは縦方向) に走査され、その走査方向に沿う線のことを 走査線 (scan line) と呼ぶ。
2000年代くらいまでは、ラスタスキャン型のディスプレイといえば、いわゆるブラウン管を用いたCRT (Cathode Ray Tube) ディスプレイが主流であった。この方式は、電子ビームが陽極 (anode)から陰極 (cathode)に向かって発射され、光が陰極側に設けられた蛍光体に当たると光を発するという仕組みになっている。
一方、現在、一般的に用いられているディスプレイは液晶ディスプレイ (Liquid Crystal Display, LCD) である。液晶とは、電流を流すことで、光の透過度が変化するような材質であり、液晶ディスプレイには、細かな液晶の素子が縦横に格子状に配置されている。この液晶素子を通過する光の強さを表示したい画像に合わせて画素ごとに制御することで、画像を表示することができる。
液晶ディスプレイにおいても、画像の更新は画面全体で同時に行われることは少なく、通常は画面の左上から右下に向かって順々に表示内容が更新される。
その方法は多少違えど、有機ELディスプレイなどの他のディスプレイも、基本的には画素ごとに電気的な制御を行うことで画像を表示するという点は同様である。
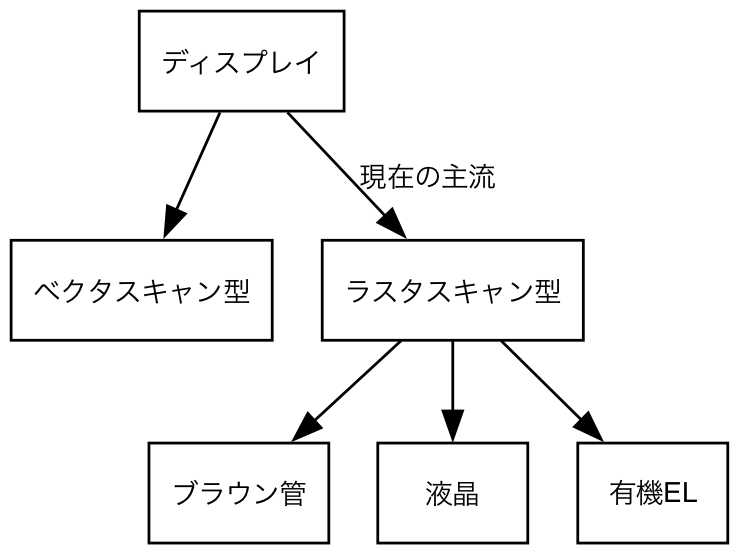
図 1.2 ディスプレイの種類#
1.2.2. 表示映像の更新#
通常、ディスプレイには リフレッシュレート という表示の更新間隔が設定されており、画面上の表示内容は1秒間に数十回程度の頻度で更新されている。一般的なディスプレイであれば、60Hzや120Hzなどのリフレッシュレートがあり、1秒間に60回、あるいは120回、表示映像が更新されていることになる。
なお、表示される動画データの側において、1秒間に含まれる画像の枚数のことを フレームレート と呼ぶ。通常のテレビ放送などは、フレームレートが秒間30フレーム程度であるため、リフレッシュレートが60Hzのディスプレイであれば、動画データを時間的に劣化させることなく表示できる。
インターレースとプログレッシブ
CRTディスプレイは残像が大きいため、特定の走査線が走査される時間的間隔を長くするために、1周期で操作される走査線を奇数行と偶数行に分けて、交互に走査する方式が用いられていた。この方式のこと インターレース (interlace) と呼ぶ。
実は、液晶ディスプレイが一般的になった現在も、伝送される映像信号のデータ量を減らす目的で、インターレース方式の映像が用いられている。例えば、いわゆる地上デジタル放送の映像は表示される映像の解像度として1920✕1080を想定しているが、実際に伝送されているのはもう少し小さな画像 (1440✕1080)で、これを受信機 (=テレビ)側で高解像度化して表示している。
一方で、BSやCSの一部放送 (NHK BS4K)などでは実際に高解像度の画像をそのまま伝送するプログレッシブ方式の映像が用いられている。
動画の解像度表示において1080iや1080pなどのように、画像の解像度 (横幅)の後に接尾辞がついている場合、iはインターレース、pはプログレッシブを表している。
1.3. デジタル画像の印刷#
プリンタとは言うまでもなく、コンピュータ等の指示に従って情報を用紙に「印刷」する装置である。
印刷とは、古くは木版などを用いて紙などに文字や絵などを写し取る技術であった。その後、15世紀の終わり頃にグーテンベルクによって活版印刷が発明され、いわゆる活字を基本単位とする版を用いて印刷する方式が広まった。活版はハンコのようなものであるので、表面の凹凸の凸の部分にインクを付けて紙に押し当てると、紙に凸部に対応する文字が「印刷」される。
一方、現在、一般的に用いられているインクジェット方式やレーザー方式のプリンタは、インクやトナーなどの印刷材料を用紙に吹き付けて印刷する方式である。この場合、活字の版を紙に押し当てるのとは異なり、紙にどのように印刷内容を吹き付けるのかを制御する必要が生じる。
単純に、印刷内容が黒か白かだけで構成されているなら、黒の部分に一様な濃さでインクを吹き付ければよいが、色の濃淡を表現するには、インクを吹き付ける量を制御する必要がある。特にデジタル画像を印刷する際には、各画素に記録されている色情報をもとに、インクの吹付け量を決定する必要がある。
しかし、通常のプリンタにはインクを水で薄めたりして濃さを調整するような機能はないため、インクの吹付け量の制御は、「塗る」か「塗らない」かの二拓になる。
1.3.1. ハーフトーニング#
ここで濃さの制御に用いられるのが ハーフトーン (halftone) で、原理は、漫画のスクリーントーンと同じである。デジタル画像からハーフトーン化された画像を得る技術を ハーフトーニング と呼び、代表的な手法には ディザリング (dithering)と呼ばれる手法がある。
ディザリングとは、画像の各画素を「塗る」場合と「塗らない」場合の二値で表現したときに、各画素に生じる誤差を計算し、その誤差が周囲の画素の濃さによって打ち消されるように画素値を決定していく手法である。
ディザリングの代表的な手法には ディザマトリックス (dithering matrix) と呼ばれる閾値のテーブルを用いる手法と、誤差拡散法 (error diffusion) と呼ばれる手法がある。
ディザマトリックスは、通常、4✕4などの小さな行列で、行列の各要素が、画像上の4✕4のブロックに対応する。4✕4のディザマトリックスの場合には、各要素は0-15の値を持ち、画像のブロック内の各画素が0-15の値に量子化されているとして大小比較を行う。すると、ブロック内での画素の平均を考えると、ディザリング前後の画素値が各ブロック内でおおよそ同じになる。
一方、誤差拡散法は、画像を走査線に沿って操作していき、各画素を「塗る」か「塗らない」かを決定する際に、生じた誤差を周囲の画素に分配に分配する。代表的な誤差拡散の手法であるFloyd-Steinbergの手法では、とある画素で生じた誤差のうち、7/16を右の画素、3/16を左下の画素、5/16を下の画素、1/16を右下の画素に分配する。

図 1.3 ディザマトリックスを用いた手法と誤差拡散法を用いた手法の比較#
実は大事なディザリング
ディザリングは、実はデジタル画像の印刷という用途以外にも、デジタル画像の表示において重要な役目を持っている。例えば、一般的なデジタル画像は各色成分が8ビットの符号なし整数で現れているので、グレースケールの画像を例に取ると、256階調の濃淡しか表現することができない。
しかし、実世界の濃淡は当然256階調のような離散的なものではないので、アナログな濃淡の信号をデジタルに直すときに、ディザリングを用いて、256階調の画素値を使いつつも、見た目としてはより滑らかな濃淡を表現することができる。
1.3.2. プリンタの基本原理#
一般的なプリンタは、コンピュータから印刷内容のデータを受け取ると、どの位置にインクを塗ればよいか (=塗らないか)をハーフトーニングにより決定する。その後、インクを吹き付けるためのヘッドを用紙に対して走査させながら、塗るべき位置にインクを吹き付けていくことで、印刷内容を用紙に写し取る。
プリンタによるデジタルデータの印刷において注意すべき点の一つにdpi (dots per inch) という単位がある。dpiとは、1インチ (約2.54cm) あたりにプリントヘッドが吹き付けることのできる点の数を表す単位である。従って、プリンタの性能を見比べたときに、dpiの値が大きければ大きいほど、より高精細な画像を印刷できることを意味する。
ただし、人間の視覚感度を考えると、おおむね300dpi程度のプリンタであれば、印刷された画像を見ても点の集合であるようには見えないため、それ以上にdpiが高かったからと言って、見た目としての印刷品質が大きく向上するわけではない。一般的なインクジェットプリンタであれば600dpi程度の商品が主流であるので、写真などの細部が重要な対象を印刷する場合であっても十分高精細な印刷結果が得られるはずである。
1.4. 写真とカメラの略史#
写真はカメラを用いることで撮影できるが、この「カメラ」という言葉の語源はラテン語で「暗い部屋」を意味する「カメラ・オブスクラ」である。カメラ・オブスクラは、箱に小さな穴 (ピンホール)を空けることで、箱の外の様子を箱の中に設置された板に投影する機材であった。
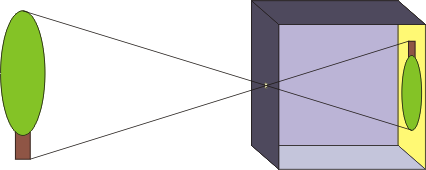
図 1.4 カメラ・オブスクラの概念図
CC-3.0 BY-SA © Wikipedia Commons 出典#
以後も初期のカメラでは、ピンホールのような小さな穴から光を通して写真を撮影する仕組みが用いられる。これは、穴が大きく空いている場合には、像がぼやけてしまうためである。現在のカメラには、通常レンズが取り付けられており、半径数センチの穴を通り抜けた光が集光されて像を結ぶように設計されている。
1.4.1. フィルムカメラ#
現在の写真のように、現実世界を写しとって保存できるようになったのは19世紀になってからのことで、初めて写真を撮ることに成功したのは、Joseph Nicéphore Niépceとされる。彼の写真は、光を当てると硬化する性質のある一種のアスファルト (bitumen of Judea)を使っており、それを塗布した樹脂板にピンホールから光を当てて、硬化していない部分を取り除くことで写真を得るというものであった。
昔のフィルムカメラのように「銀塩」(= ハロゲン化銀)を使って写真の撮影を試みたのは、Henry Talbotであり、彼のカメラは現在流通しているフィルムカメラのように、いわゆる「ネガ画像」を現像によって取得できた。そのためTalbotの方式は、Niépceの写真と違い、何枚も同じ写真を焼き増しすることができた。
20世紀のはじめになると商用のフィルムカメラがコダック社により発売された。この頃になると、フィルムがセルロイドで作られるようになり、それまでの紙のフィルムよりも写真の品質が安定するようになった。
銀塩を感光剤として用いる写真は、フィルムに銀塩を塗布したものを用いる。銀塩に光が当たると、ハロゲン化銀の一部が銀結晶に変化する。
この銀結晶は微量であるため目視では確認はできないが、これを現像液に浸すと、銀結晶の周囲のハロゲン化銀だけが銀に変化し、光があたった部分が暗くなる。これにより、いわゆる「ネガ画像」(通称「ネガ」) が写ったフィルムが得られる。
このネガを通した光を印画紙に当てて、再び現像と同様の工程を経ると、ネガのネガとして元の画像である「ポジ」が得られる、というのが銀塩を用いた写真の基本的な仕組みである。

図 1.5 フィルムカメラで撮影されたネガ画像
CC BY-SA 3.0 © Wikimedia Commons 出典#
{kind=link}
1.4.2. デジタルカメラ#
デジタルカメラ の基盤技術であるCCD (Charged-Coupled Device)は、金属酸化膜半導体 (MOS, metal-oxide semiconductor)を用いて1970年に開発された [2]。開発に携わったWillard BoyleとGeorge E. Smithは2009年にノーベル物理学賞を受賞している。
CCDを用いた二次元イメージセンサにはいくつかの構造があるが、その一つであるインターライン方式のCCDイメージセンサ(図 1.6)は、各列 (あるいは各行)ごとにCCDが直列に繋がっており、各画素に光があたって電荷が生じると、その電荷をバケツリレーのように隣の画素に渡していく。各列の末端にあるCCDは横方向 (あるいは縦方向)に隣の列と繋がっており、各列の電荷は隣の列へと渡される。
最後に、集められた電荷がアナログ-デジタル変換されて離散的な画素値の情報として記録される。

CCDをイメージセンサに用いたデジタルカメラは1975年にコダック社で開発された。製造されたデジタルカメラは100×100画素の解像度を持つカメラであった。
一般向けに「開発」されたデジタルカメラは富士写真フイルム (現在の富士フイルム)が1988年に発表したFUJIX DS-1Pであった。ただし、実際には一般向けに販売されることはなく、実際には1989年にFUJIX DS-Xが一般向けに「販売」された。
ただし、FUJIX DS-Xは非常に高価であったため、一般向けに広く受け入れられたデジタルカメラとしてはDycam Model 1が広く知られている。
なお、現在、多くのデジタルカメラのイメージセンサにはCCDではなく CMOS (相補型金属酸化膜半導体)が広く用いられている。
CMOSは1画素のCCDが二次元に並べられたような構造となっており、1画素ごとに光電効果により生じる電荷を読み出すことができる。当初、CMOSは画素ごとの個体差により生じるノイズが問題視されていたが、CMOSはCCDに比べて安価に作成でき、読み出し速度が早いという優位性があり、徐々に性能改善が進んだことで、今日のデジタルカメラの標準となった。
CMOSイメージセンサがデジタルカメラに初めて搭載されたのは1996年に発売された東芝のアレグレット PDR-2であるとされている。
なお、現在、市販のデジタルカメラのほとんどがCMOSイメージセンサを採用しているが、産業用カメラやレントゲン写真器のような画質や感度が重要となる用途では、CCDイメージセンサが用いられることも多い。
写真とカメラの歴史
今日の「カメラ」という名前は「カメラ・オブスクラ」という室外の様子を室内に投影する仕組みに由来する。
CCDイメージセンサは初期のデジタルカメラに広く用いられていた。現在でも産業用や医療用の一部の応用では広く用いられている。
CMOSイメージセンサは、安価に作成でき、CCDよりも読み出しの速度が速い。当初、画質に課題を抱えていたが、現在は性能改善によりイメージセンサの主流となっている。
練習問題
あなたのスマートフォンで撮影できる写真の解像度を確認しなさい。スマートフォンのスペック表を確認しても良いし、実際に撮影した写真のプロパティを確認しても良い。
次に、適当なミラーレスカメラ (おおむね20万円以上するカメラ) のスペック表を確認して、撮影できる写真の解像度を確認しなさい。
両者はおよそ同程度の解像度を持っているはずであるが、一般にミラーレスカメラの方が高精細な画像が撮影できる。その理由を考察しなさい
1.5. プログラミング演習#
レポートは テンプレートファイル を使用して作成してください。また、ファイル名は 「(7桁の学籍番号)_第x回_画像処理レポート.docx」 (xの部分は何回目の課題なのかを記入)に変更してください。
課題作成上の注意
課題を作成する際には、プログラムは別に .py ファイルで作成して、本レポートと一緒に圧縮したうえで提出してください。また、Jupyter Notebook形式のファイル (拡張子が.ipynb)のものは受け付けません。
加えて、プログラムを添付したのみで内容に関する説明や結果に関する考察のないもの、単なる結果の羅列になっているもの(またはそのように見えるもの)は採点しませんのでご注意ください。
OpenCVによる画像形式の変換
OpenCVの cv2.imread ならびに cv2.imwrite を用いて、PNG画像をJPEG画像に変換し、変換前後の画像サイズを比較しなさい。
JPEG形式の画像圧縮
OpenCVの cv2.imwrite を用いてJPEG形式の画像を保存する時、第3引数に [cv2.IMWRITE_JPEG_QUALITY, 95] のようなオプションを指定することで、画像の圧縮率を変更することができる。
圧縮品質 (上記の例では95) を10, 20, ..., 100のように変化させながら同じ画像を保存したとき圧縮品質と得られた画像サイズの関係をグラフにし、その関係について考察しなさい。
ディザリングのアルゴリズム (発展)
Floyd-Steinbergの誤差拡散法を実装して、グレースケール画像をディザリングするプログラムを作成しなさい。
また、カラー画像の各チャンネルに対して、同様のディザリングを行うプログラムを作成しなさい。得られた結果から、グレースケール画像とカラー画像のディザリングの違いについて考察しなさい。