5. 物体検出の基礎#
画像中から、人や車といった特定の物体を検出することは、応用的にも画像処理の重要なタスクの一つである。物体が認識できる、ということは、その画像中にとある物体が「存在する」ということにとどまらず、画像上で物体が存在する「位置」も含めて特定することを意味する。
本節では、物体検出の導入として、テンプレート・マッチング、Hough変換、動的輪郭法といった基本的な図形の検出、特に図形の存在する位置を特定する技術について紹介する。
より一般的な物体の認識を伴う物体検出の技術については、次節 画像特徴量 にて取り上げる。
クイズ
あなたは駐車場の管理者で、駐車場の監視カメラの映像 (真上から撮った映像とする) を見て、駐車場に停まっている車の数を数えたい。ただし、車には様々ないろや形があり、あなたのコンピュータはこれら全てを認識できるほど賢くはない。非常に残念なことに、分かるのは、そこに四角があるかどうかだけだ。
この状況で、あなたはどのようにして駐車場に停まっている車の数を数えることができるだろうか?
参考資料
『ディジタル画像処理 改定第二版』 P.233 第11章 パターン・図形・特徴の検出とマッチング
5.1. テンプレート・マッチング#
テンプレート・マッチングとは、とある画像の中に、特定のパターンを持つテンプレート画像と似た画像を探す技術である。以下では、次の数独問題の画像から特定の数字がどこに存在するかをテンプレート・マッチングにより探索する問題について考えてみよう。
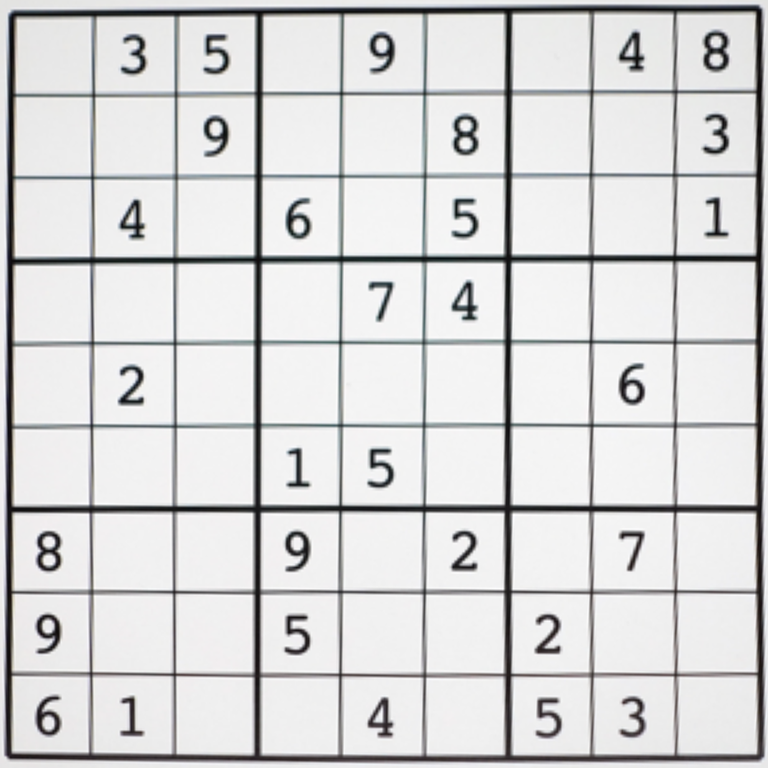
図 5.1 本項で扱う数独問題の画像#
今回はテンプレートとして、以下の「1」, 「2」, 「3」 の数字が書かれた画像を用意した。
1 |
2 |
3 |
|---|---|---|
|
|
|



以下ではまずテンプレート・マッチングに用いられる画像同士の類似度指標について見ていく。
5.1.1. 画像の類似度#
画像の特定の領域がテンプレート画像と一致するかどうかを調べたい場合、単純には画像と画像の差を考えればよいだろう。このような画像の差や類似度としては二乗誤差和 (SSD, sum of squared differences)や絶対誤差和 (SAD, sum of absolute difference) がある。2つの大きさが等しい画像 \(I\) と \(J\) のSSDならびにSADは次の式で計算できる。
これらの指標は、画像 \(I\) と \(J\) をベクトルとして見なしたときには、それぞれ「L2ノルムの二乗」と「L1ノルム」に対応している。
SSDやSADは値が小さくなるほど画像同士が似ていることを示す距離指標だが、反対に値が大きいほど画像同士が似ていることを表す類似度指標もある。その代表例が 正規化相互相関 (NCC, normalized cross-correlation) である。NCCは次の式で計算できる。
NCCは、画像 \(I\) と \(J\) をベクトルと見なした場合には、二つのベクトルがなす角に対する余弦を表している。
数独問題の画像上から「2」のテンプレートに近い画像領域を検索した結果を以下に示すが、SSD (を0-1の範囲の類似度になるように正規化したもの)は、0-1の範囲で様々な値を取るのに対して、NCCは全体的に1に近い値を取る傾向があることが分かる。
ただし、NCCの結果の最小値と最大値が0-1の範囲になるように再度正規化すると、(この例に限っては) 実質的な差はほとんどないことが分かる。
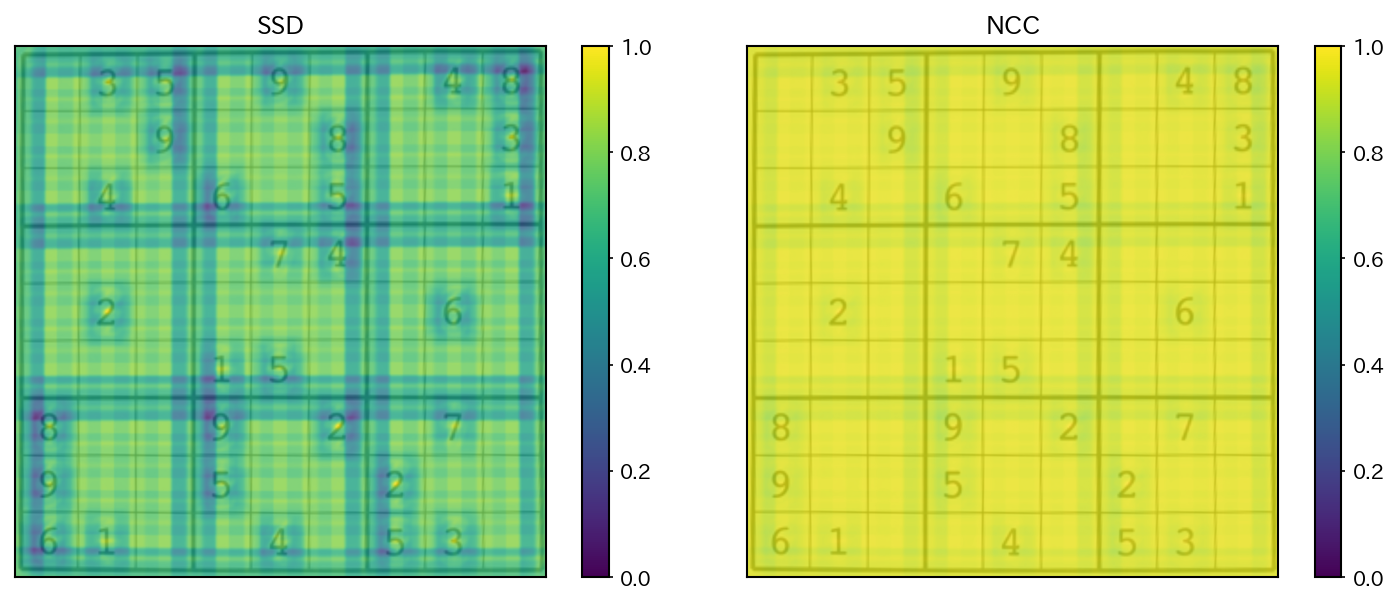
図 5.2 SSD/NCCによるテンプレートと画像の類似度#
また正規化相互相関と類似した手法には画像を表すベクトル \(I\) と \(J\) の間でPearsonの相関係数と同様の値を計算する ゼロ平均正規化相互相関 (ZNCC, zero-mean normalized cross-correlation) がある。ZNCCはPearsonの相関係数と同様に次の式で計算できる。
ここで \(\bar{I}\) は画像 \(I\) の平均値、\(\bar{J}\) は画像 \(J\) の平均値である。ZNCCは画像の平均値を引き算して輝度を調整するため、画像の明るさの影響を受けづらい。
NCCとZNCCの比較を以下に示すが、ZNCCの方が、テンプレートがマッチする箇所でより周囲から際立って高い類似度を示すことが確認できる。
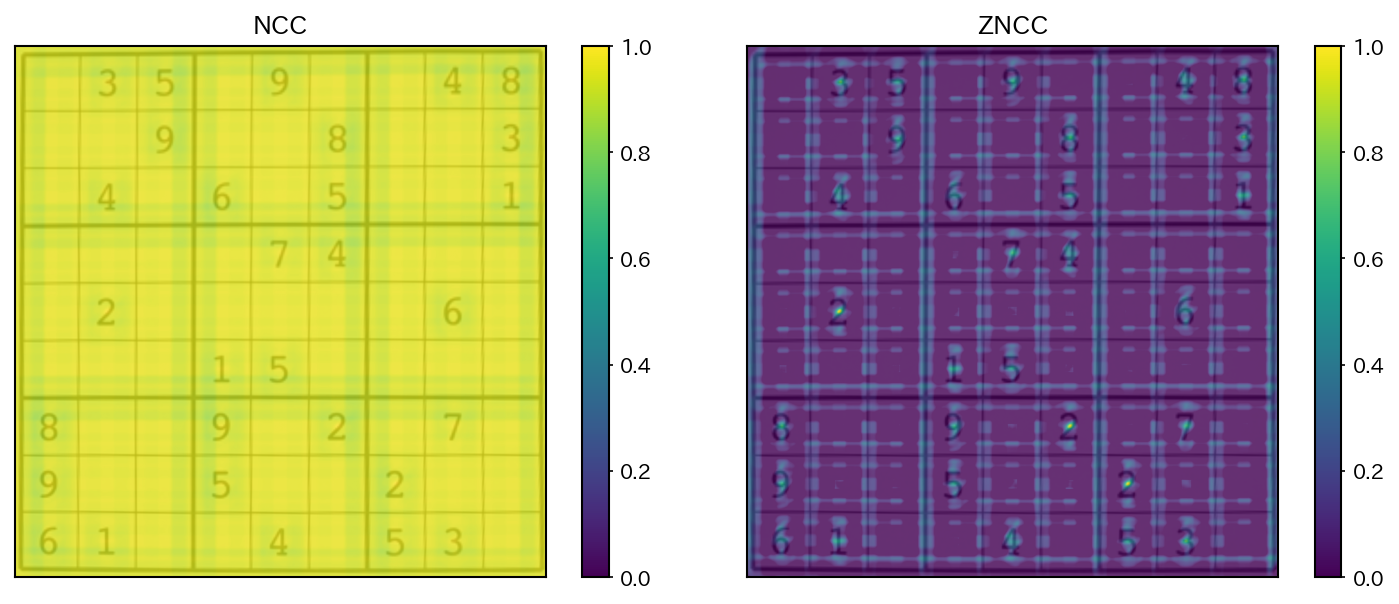
図 5.3 NCC/ZNCCによるテンプレートと画像の類似度#
まとめ: テンプレート・マッチングのための類似度指標
テンプレート・マッチングにはSADやSSDなどのように、画像の断片をベクトルと見立てた際の距離指標が使われる
Pearsonの相関係数に基づくZNCCは、画像の明るさの影響を受けづらく、より構造的な類似度を測ることができる
また、テンプレート・マッチングとは別に、画像の類似度には知覚的な要素を考慮したSSIMや深層学習器を用いるLPIPSのような指標もある
5.1.2. Chamferマッチング#
ここまでに紹介したZNCC等によるテンプレート探索は、入力画像上のすべての位置に対してテンプレート画像との距離を求める必要があった。この処理は、並列計算などにより高速化できる余地があるものの、画像のサイズが大きくなると、それに応じて計算量が膨大になってしまう。
本項で紹介する Chamferマッチング は、入力画像とテンプレート画像のそれぞれを距離画像とエッジ画像として表現し直すことにより、テンプレートをある初期位置からどの方向にどれだけ動かせば、最もマッチする位置に到達するかを逐次計算し、テンプレート位置を最適化する手法である。
Chamferマッチングを行うためには、いわゆる 距離画像 の事前計算が必要となる。距離画像は以下の表 5.2 に示すように入力画像からCannyエッジ検出により1画素幅のエッジを取得した後、そのエッジからの最短距離を各画素から計算することで得られる。
入力画像 |
Cannyエッジ検出 |
距離画像 |
|---|---|---|
|
|
|


今、入力画像 \(I\) の距離画像を \(I_{\text{DT}}\) とし、テンプレート画像 \(T\) のエッジ画像を \(T_{\text{E}}\) と表すことにしよう。この表現を用いる場合、テンプレート画像を入力画像上の位置 \((x, y)\) に配置したときの類似度 \(S(x, y)\) は次の式で表せる。
ただし、\(x'\), \(y'\) はテンプレート画像の画素の位置全体を動くものとし、 \(K\) はテンプレート画像のエッジ画素の数を表すものとする。
この指標はテンプレート画像のエッジが、入力画像の距離画像上で「よりエッジに近い位置」に来るほど値が小さくなる。この関数を最小化する位置 \((x, y)\) を求めるために、Chamferマッチングでは \(S(x, y)\)の \(x\), \(y\) に関する偏微分を考える。
この式に現れる \(I_{\text{DT}}\) の偏微分は距離画像のエッジのようなもので、事前計算可能である。これらの偏微分の値を用いて、最急降下法の要領で \(S(x, y)\) を最小とするようなテンプレートの位置 \((x, y)\) を求めるのである。
Chamferマッチングは、SSDやZNCCなどの類似度手法を用いる場合と異なり、全ての \((x, y)\) に関するマッチングは不要で、適当な初期位置を与えることができれば、そこから勾配法により最適なテンプレート位置を決定できる。
以下に格子状に並んだ適当な初期点からChamferマッチングを実行した結果を示す。
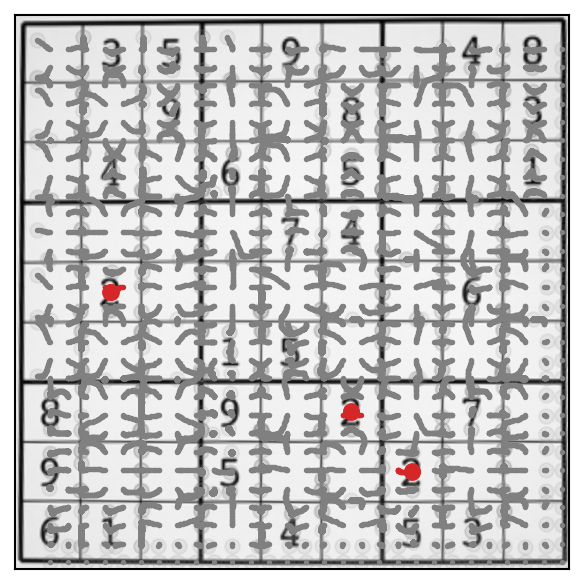
図 5.4 Chamferマッチングの結果#
この結果を見てみると、いくつかの初期点からスタートして正しく「2」のマスの中央に到達している軌跡があることが確認できる。
その一方で、テンプレートの初期位置が適当でない場合には、局所解として不適切な位置でテンプレートが滞留する可能性もある。このような問題を防ぐため、入力画像とテンプレート画像の解像度を落とした画像における全探索等で初期位置のあたりを付けておき、有効と考えられる初期点に対して、元の画像サイズでChamferマッチングを行う、といった処理が一般的である。
まとめ: Chamferマッチング
Chamferマッチングは距離画像とエッジ画像を用いて、テンプレート位置を最急降下法の要領で最適化する方法である
Chamferマッチングは前述のテンプレート・マッチングと異なり、全画素に対してのマッチングが不要である
その一方、Chamferマッチングの結果は初期のテンプレート位置に強く依存するため、良い初期位置を与えるための工夫が必要である
5.2. Hough変換による図形の検出#
5.2.1. Hough変換#
Hough変換とは 1962年にPaul Houghが提案した、画像中の特定の図形を検出するアルゴリズムである。Hough変換は、特に直線や円などの少ないパラメータで記述可能な図形を検出するために広く用いられている。
Hough変換は、画像中のエッジを検出し、それらのエッジがどのような図形を形成しているかを解析することで、図形の位置や形状を特定する。そのエッジ上の各点 \((x_i, y_i)\) について、その点を通る直線の集合を考える。そのような直線は \(y = \hat{a} x + \hat{b}\) のような形で表せる (画像上の座標と、パラメータを区別するため、パラメータには \(\hat{a}\) のようにハット記号をつける)。また、\(\hat{a}\)について、\(\hat{b}\)は \(\hat{b} = y_i - \hat{a}x_i\) という直線の式で表せる・
したがって、直線のパラメータ \((\hat{a}, \hat{b})\) に関する二次元座標系(以後、「パラメータ座標」と呼ぶ) で、 \((x_i, y_i)\) を通る直線の集合は、\(\hat{b} = - \hat{a}x_i + y_i\) という直線として表せる。反対に、\(\hat{a}\)-\(\hat{b}\) 空間における点 \((\hat{a}, \hat{b})\) は画像上では1つの直線に対応している。
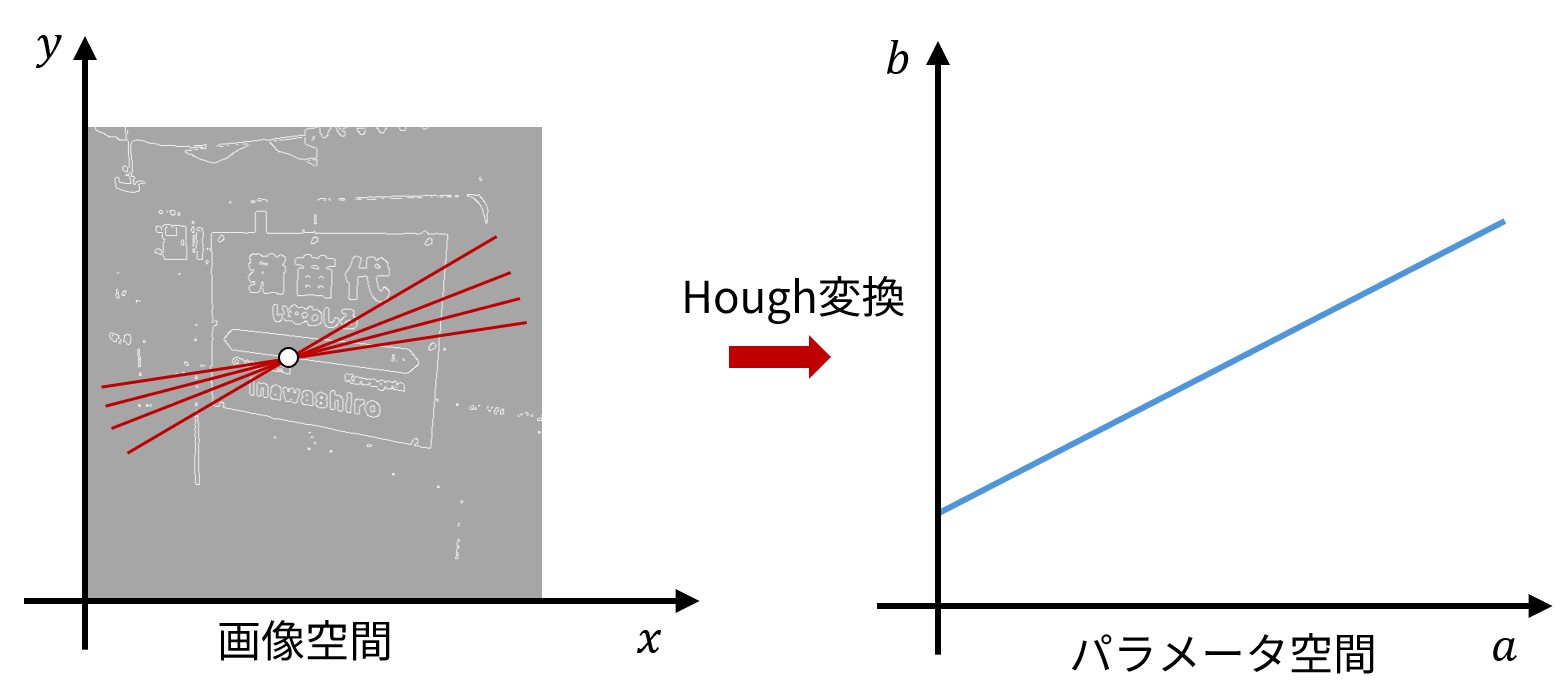
図 5.5 Hough変換の概念図#
反対に、画像上のエッジにある各 \((x_i, y_i)\) について \(\hat{a}\)-\(\hat{b}\) 空間直線を引くと、画像上に存在する直線に対応する点 \((a, b)\) で多くの直線が交わる (エッジと直線の言葉遣いの違いに注意すること)。以上のようにHough変換は、
画像上の点をパラメータ空間の直線に写す
パラメータ空間上の点を画像上の直線に写す
という効果を持つ。
計算機上でHough変換を実装するためには、一定の区間の \((\hat{a}, \hat{b})\) を有限個のセルに分割しておく。その上で、\(\hat{a}\)-\(\hat{b}\) 空間上で直線が通るセルに投票を行っていき、票数が多いセルに対応する \((\hat{a}, \hat{b})\) が画像上で直線を形成しているとみなす。
実装上の問題#
しかし、直線の検出のために \((\hat{a}, \hat{b})\) というパラメータを用いる場合、理論的には \((\hat{a}, \hat{b})\) が実数全体の値を取りうるにも関わらず、それを有限区間に限定した上で、さらにセルに分割しなければならない、という問題がある。
実際、画像の中に存在する直線が一定の区間の \((\hat{a}, \hat{b})\) に収まっている保証はなく、また、パラメータ空間のより広い範囲を扱おうとする場合には、 セル上の値を保持するために多くのメモリを消費する ことになる。従って、\(\hat{a}\)-\(\hat{b}\) 空間上を有限個のセルに分割するというのは実際には困難である。
このような問題を解決するため、直線検出においては、 \((\hat{a}, \hat{b})\) とは異なるパラメータで直線を表現することが多い。例えば、直線の方程式を
とおいて、Hough変換に用いるパラメータ空間を \((\hat{\rho}, \hat{\theta})\) で表す場合を考えよう。ここで \(\hat{\rho}\) は原点と直線の「符号付き」距離を表し、 \(\hat{\theta}\) は原点から直線に下ろした垂線の傾きを表す (図 5.6 を参照)。
なお、ここで言う「符号付き距離」とは、直線と原点から直線に下ろした垂線の交点 \(H\) が第一象限あるいは第二象限にある場合に正、第三象限あるいは第四象限にある場合に負の値を取るような距離である。
このようなパラメータを用いるHough変換を提案者の名前から Duda-HartのHough変換 と呼ぶ。
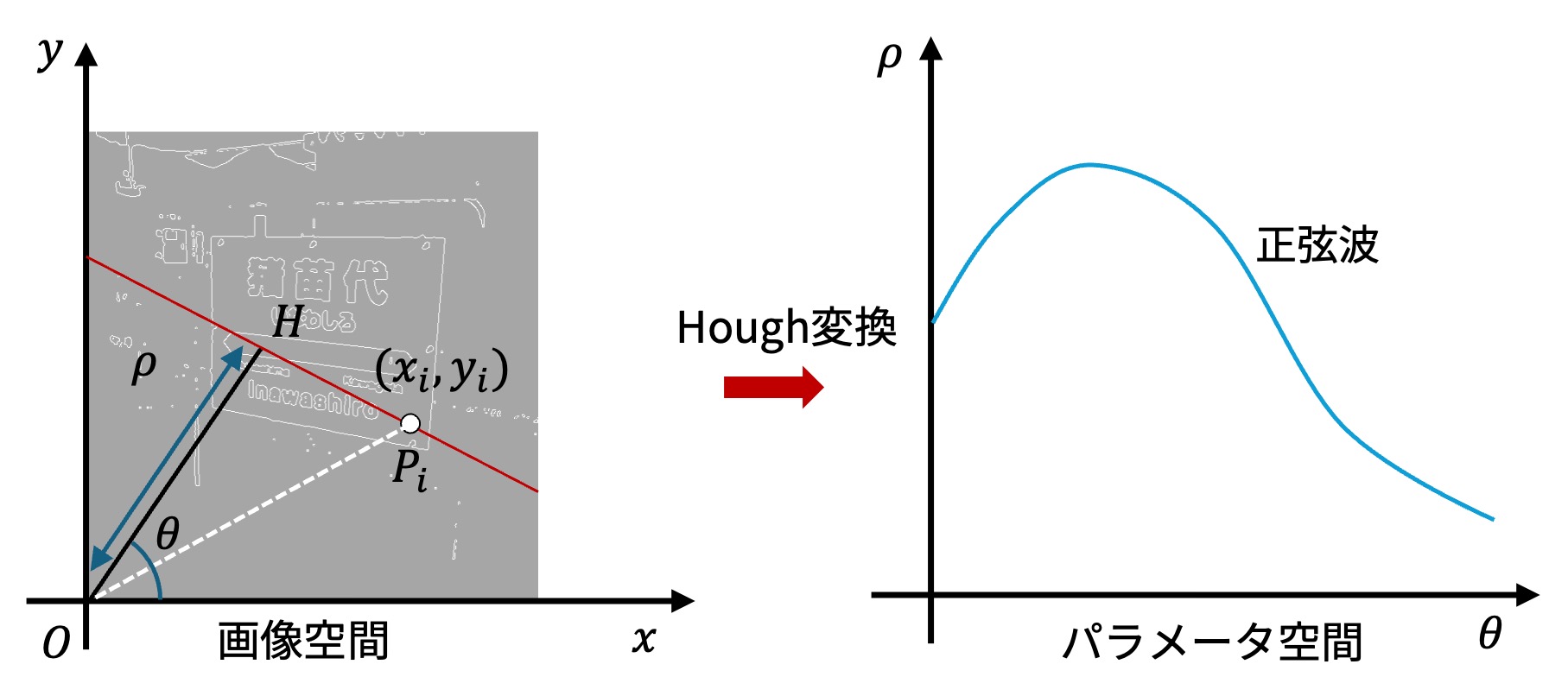
図 5.6 直線の原点からの距離と傾きを用いたHough変換#
この際、原点との符号付き距離 \(\hat{\rho}\) は画像の対角線の長さを \(L\) として、\([-L, +L]\) という有限の範囲に収まっている。また、直線の傾きと垂直な方向を表す \(\hat{\theta}\) も \([0, \pi]\) という有限の範囲に収まる。したがって、この区間を有限のセルで分割すれば、任意の画像上の直線がパラメータ空間の中に収まることが保証される。
結論から言うと、画像上の一点を通る直線の集合は、\((\hat{\rho}, \hat{\theta})\) を用いたパラメータ空間上では正弦波を描く。この事実を確かめてみよう。
図 5.6 において、y軸と直線 \(OP_i\)がなす角度を \(\phi\) と置くと、
と書ける。すると、\(\angle P_i OH\) は \(\hat{\theta} + \phi - \frac{\pi}{2}\) と書ける。従って、 \(D = \sqrt{x_i^2 + y_i^2}\) として、\(\hat{\rho}\) を表すと、
と書ける。このことから、パラメータ \((\hat{\rho}, \hat{\theta})\) を用いると、画像上の一点はパラメータ空間上の正弦波に変換されることが分かる。
Duda-HartのHough変換を用いて画像上から直線を検出した結果を以下に示す。
入力画像 |
Cannyエッジ検出 |
|---|---|
|
|
パラメータ空間の投票数分布 |
Hough変換 |
|
|

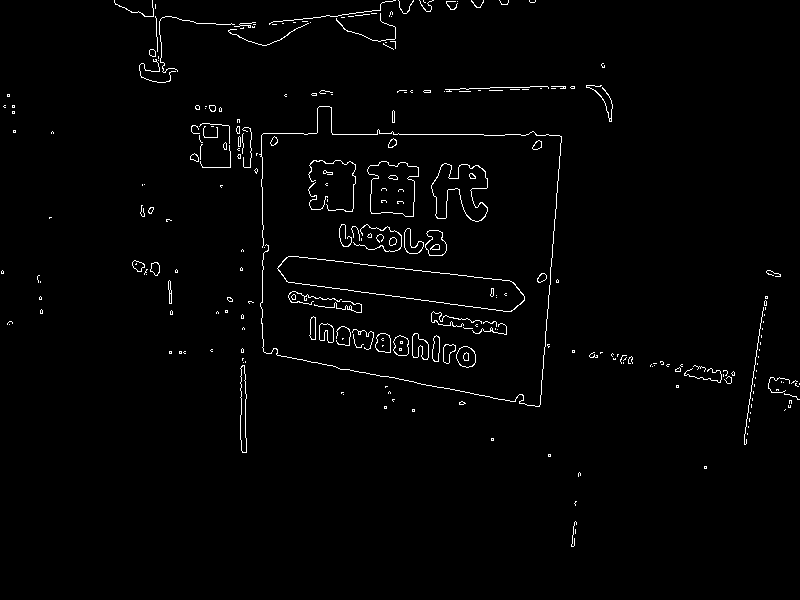
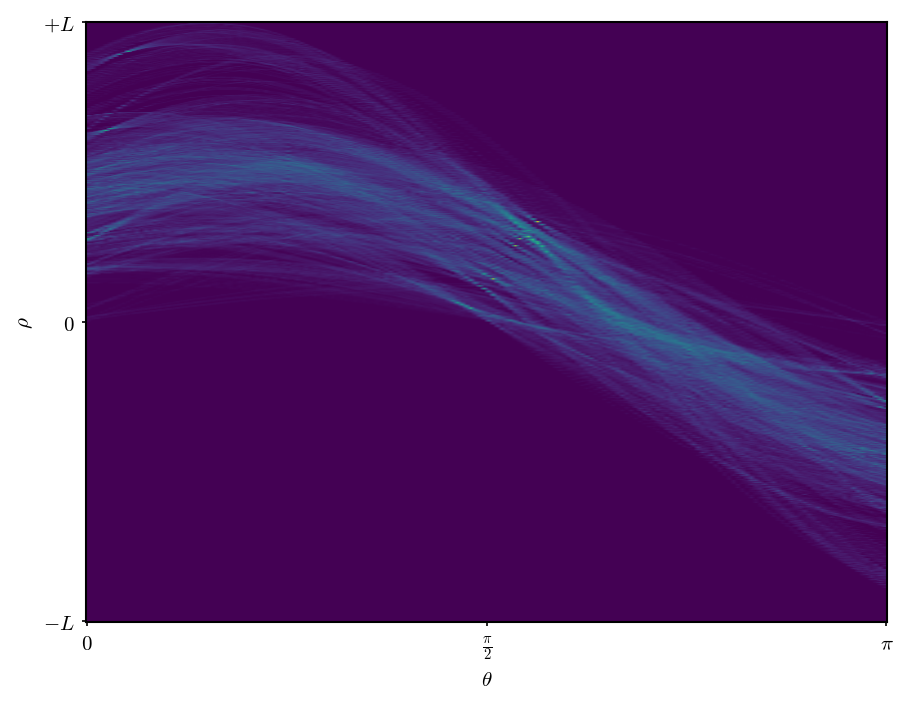

結果から分かる通り、Hough変換により、エッジ上の各点が正弦波を描き、パラメータ空間上で多くの曲線が交わる箇所が点在していることが確認できる。このうち一定以上の投票数を集めたものを画像空間で描画したものが右下の画像で、検出された直線が画像のエッジ上を通っていることが分かる。
5.2.2. ランダム化Hough変換#
ここまでに紹介した通常のHough変換は、エッジ上のすべての点についてパラメータ空間上での直線や正弦波を描画する必要があり、入力画像の大きさや、パラメータ空間の分解能に応じて計算量が増大するという問題がある。しかも、このようなパラメータ空間上に描画される正弦波等の上の点は、ほとんどが画像上に存在しない図形に対応しており、計算的にも無駄が多い。
また、図形のパラメータ数も、直線なら2つで済むが、円ならば3つ、楕円ならば5つとパラメータ空間の次元が増えることも、Hough変換の計算量を増大させる原因である。
このような問題を防ぐために、ランダム化Hough変換では、パラメータを \(n\) 個持つ図形を検出するために、\(n\) 点をランダムに選び、その \(n\) 点から決まる図形のパラメータに対応する パラメータ空間上の1点のみ に投票を行う。
この操作は、エッジ上の点をランダムに \(n\) 個選ぶ操作を繰り返すだけなので、精度とのトレードオフはあるものの、画像のサイズやパラメータ空間の分解能、パラメータ空間の次元等に依存せず、一定の計算量を保つことができる。
以下に、ランダム化Hough変換によるパラメータ空間上の投票数と、直線の検出結果の例を示す。
パラメータ空間の投票数分布 |
Hough変換 |
|---|---|
|
|
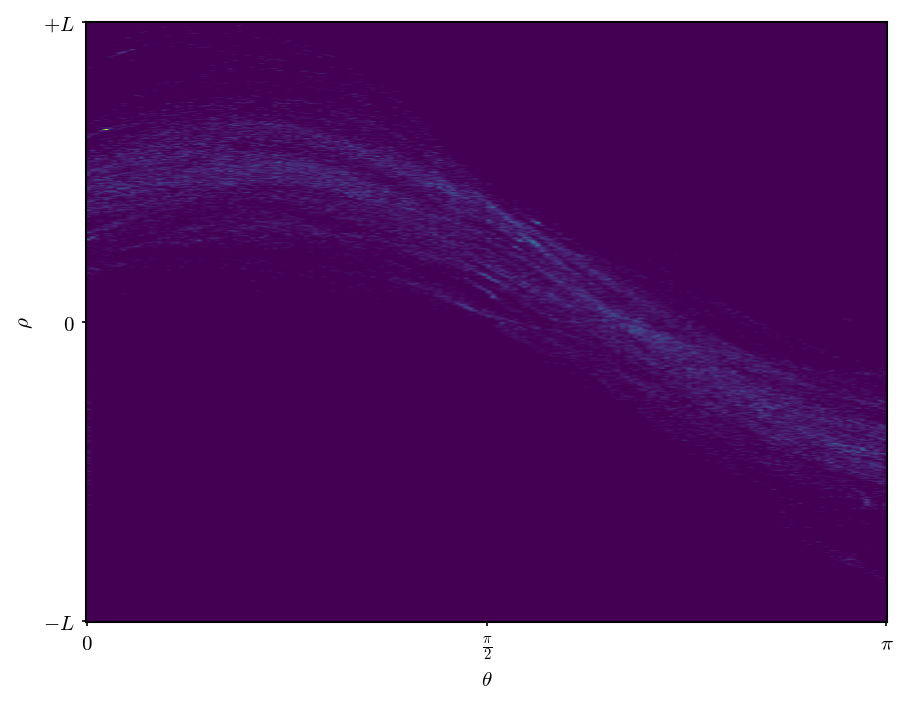

なお、上記の例では、従来のHough変換において直線のパラメータを求める操作をランダムに選んだ2点から決めるという変更に留めたが、実際のランダム化Hough変換では、Houghテーブル上に投票数の他、近似される線分のパラメータの保持・更新を行うなど、もう少し複雑な処理を行っている。
このあたりの詳細に興味のある読者は、文献 [12] を参照してほしい。
5.2.3. 一般化Hough変換#
ここまでに紹介したHough変換は、直線や円などのように、一定数のパラメータによって図形が定義されるような図形を検出する方法であった。
しかし、より一般的な図形を表すためには、パラメータ数をさらに増やす必要も生じるほか、そもそもパラメータによって上手く表すことができない図形もあるだろう。
このような場合に用いられるのが一般化Hough変換である。一般化Hough変換では、図形を表すために、図形の姿勢を表すパラメータとして並進ベクトル \((t_x, t_y)\), 回転角度 \(\theta\), スケール \(s\) の4つを用いる。
さらに、図形自体の表現を輪郭線上の点の集合として表す。図形上の点を \(\mathbf{x}_i = (x_i, y_i)\) としたとき、各点で次の2つの値を計算しておく。
\(\mathbf{x}_i\) から図形上の基準点 (例えば重心) に向かうベクトル \(\mathbf{v}_i\)
\(\mathbf{x}_i\) におけるエッジの傾き \(\psi_i\)
この時、各 \(\mathbf{v}_i\) は、\(\mathbf{v}_i = (r_i \cos \alpha_i, r_i \sin \alpha_i)\) のように2つのパラメータ \((r_i, \alpha_i)\) で表しておく。
このようにして得られた各点のパラメータは \((r_i, \alpha_i, \psi_i)\) の3つのパラメータで表されるが、ここで、エッジの向き \(\psi_i \in [0, \pi]\) を量子化して \(N\) 個のビンに分けておく。すると、\(\psi_1, \ldots, \psi_N\) の各ビンに対して、\((r_i, \alpha_i)\) の値を格納した形状定義表を作ることができる。
この形状定義表を用いると、任意の形状に対してHough変換を行うことができる。具体的には、エッジ上の点 \((x, y)\) に対して、次のような処理を行う。
投票先の計算は、全ての取りうる \((\theta, s)\) に対して \((t_x, t_y)\) の値を計算することで行われる。今、図形の傾きが \(\theta\) であると考えると、傾ける前のエッジの向きは \(\psi - \theta\) であるので、この値に対応する \((r_j, \alpha_j)\) の値を全て取り出す。
基準点が原点であるとき、変形前の図形上点 \((x, y)\) は、その定義から
と書けるのだった。この点を、回転、スケール、並進の順で座標変換すると、変形後の図形上の対応点 \((x', y')\) は次のように表せる。
したがって、各 \((\theta, s)\) に対して、取りうる並進量 \((t_x, t_y)\) は次のように表せる。
以上のようにして、 \((\theta, s, t_x, t_y)\) に対して投票を行っていくと、通常のHough変換と同様の方法で、任意の図形 (輪郭形状) を検出することができる。
まとめ: Hough変換
Hough変換は直線や円など、少数のパラメータで定義される図形を画像中から検出する手法である
Hough変換はエッジ上の点を通る全ての図形を、パラメータ空間上の別の図形に移す変換である
パラメータ空間上で多くの投票が集まったパラメータが画像上での図形に対応する
Hough変換には、計算量を削減するためのランダム化Hough変換や、任意の図形を検出可能な一般化Hough変換などのバリエーションがある
5.3. 動的輪郭法#
物体の輪郭線を閉曲線として検出する古典的な手法には 動的輪郭法 (active contour method) がある。
動的輪郭法の代表的な手法は、いずれも1988年に提案された Snakes法 [13] と レベルセット法 [14] の2つである。ただし、レベルセット法が画像中の輪郭線検出に応用されたのは少し後で、1997年のことである [15] 。
5.3.1. Snakes法#
Snakes法は、初期の輪郭線をエネルギー関数を最小化するように徐々に変形していくことで、画像中の輪郭線にフィッティングする手法である。
Snakes法のエネルギー関数 \(E\) は曲線のパラメータ \(s \in [0, 1]\) に対して連続的に次の式で表される。
ここで、 \(E_{\text{internal}}\) は曲線そのものの状態から決まるエネルギー関数で、一般的には、曲線の滑らかさを表す関数として次のように定義される。
ここで、第1項は曲線がより短くなる方が低い値を、第2項は曲線がより滑らかな方が低い値を取るようなエネルギーを表す。
また、\(E_{\text{external}}\) は画像のエッジやコントラストなど、画像の状態から決まるエネルギー関数で、一般的には次のように定義される。
この式は、画像のエッジが強いところエネルギーが小さくなる。従って、このエネルギーを小さくするように曲線を更新すると、曲線がエッジに引き寄せられる。
Snakes法を離散的な曲線に適用するためには、曲線を \(N\) 個の点 \(\mathbf{x}_i\) で近似する。
具体的には、 \(E_{\text{elas}}(s)\), \(E_{\text{curv}}(s)\) ならびに \(E_{\text{image}}(s)\) の式を離散化して、次のように定義する。
すると、各エネルギーの \(x\) ならびに \(y\) に関する偏微分は次のように表せる。
ただし、\(\mathcal{H}(\mathbf{x}_i)\) は画像のヘッセ行列を表し、
のように定義される。
以下に、この式に従ってSnakes法を実装した結果を示す。頂点位置の更新方向は、勾配の方向とは逆の方向であることに注意すること。
しかし、Snakes法は初期の輪郭線を徐々に変形していくため、2つ以上の図形を一度に検出するなど、輪郭線のトポロジーが途中で変わるような変形を行うことはできない。
5.3.2. レベルセット法#
レベルセット法の元となるアイディアは、初期の曲線 \(C_0\) を徐々に変形させていくことで、別の曲線を表すというものである。
曲線の表現#
ここで曲線 \(C\) が、パラメータを\(p\) とする曲線であって、時刻 \(t\) によって変形するとして \(C(p, t)\) と定義する。ここで、曲線は各時刻 \(t\) において、法線 \(\mathbf{n}(p, t)\) 方向に微小変化するとする。この変化量は曲線の曲率 \(\kappa(p, t)\) の関数 \(F\) で決まるとすると、曲線の関数の時刻 \(t\) における偏微分は
この定式化自体はSnakes法のそれと似ているが、この式は曲線が途中で2つに分かれるといったトポロジーの変化を扱うことができない。
そこで、レベルセット法では、曲線 \(C\) を、あるスカラー値関数 \(\phi(x, y, t)\) のゼロ等値面 (zero-level set)として、
のように表すことにする。ここで用いられる関数 \(\phi\) を レベルセット関数 と呼ぶ。以下の説明では、便宜上、レベルセット関数 \(\phi\) の値が、曲線 \(C\) の内側で正、外側で負の値を取るように定義することにする。
レベルセット法を二次元図形の輪郭検出に用いる場合、座標 \(\mathbf{x} = (x, y)\) に加えて、時刻パラメータ \(t \in [0, 1]\) を変数とするスカラー値関数 \(\phi(x, y, t)\) を考える。その上で、 \(\phi(x, y, t) = 0\) となるような点の集合
時刻 \(t = 0\) における輪郭線を \(C_0 = \{ \mathbf{x} : \phi(x, y, 0) = 0 \}\) と定義する。また、\(C_0\) における曲線上の各点での内向きの法線ベクトルを \(\mathbf{n}(\mathbf{x})\) と表すことにする。
ここで、曲線の移動速度を曲線の曲率 \(\kappa(\mathbf{x})\) の関数として \(F[\kappa(\mathbf{x})]\) のように表すとしよう。すると、時刻 \(t\) における曲線の形状は次の式で表せる。
この定式化を用いると、\(\phi(x, y, t)\) の取り方の如何によって、二次元の輪郭線のトポロジー変化を扱うことができる。
曲線の変形#
レベルセット法では、(5.2) の式を、より具体的に次の式で表す。
ここで、\(g(|\nabla I|)\) は画像のエッジ強度を表す関数で、エッジストップ関数 (edge stopping function) と呼ばれる。具体的には画像の勾配 \(|\nabla I|\) を変数とし、\(g(0) = 1\) かつ、 \(\lim_{r \to \infty} g(r) = 0\) となるような関数 (例えばガウス関数) や
のような関数を用いることが多い (\(k\) はパラメータで最大のエッジ強度の定数倍とすることが多い)。
また、曲線の移動方向 \(\mathbf{n}\) ならびに曲率 \(\kappa\) は、関数 \(\phi\) を用いて次のように表す。
レベルセット法は \(\phi\) のゼロ等値面を曲線として扱う一方で、関数 \(\phi\) 自体は任意の \((x, y)\) で値を取るので、離散的には初期の\(\phi(x, y, 0)\) を画像のように用意して、各画素 \((x, y)\) における値 \(\phi(x, y, t)\) を徐々に更新していく。
以下に、レベルセット法による輪郭検出の様子と、その際のレベルセット関数の変化の様子を示す。
以上のように、レベルセット法は、仮に初期輪郭が1つの閉曲線であったとしても、2つ以上の図形を検出することができる。ただし、Snakes法と比べると実装が複雑で高速化には多少の工夫が必要になる点は注意が必要である。
まとめ: 動的輪郭法
動的輪郭法は、初期の輪郭線を何らかのエネルギー関数を最小化する形で、画像中の物体の輪郭線にフィッティングする手法である
Snakes法は、曲線に関するエネルギー関数を最急降下法の要領で最小化することで物体の輪郭線を検出する
レベルセット法は、曲線を高次元のスカラー値関数のゼロ等値面として表現することで、複数の図形を同時に検出することができる手法である
5.4. プログラミング演習#
レポートは テンプレートファイル を使用して作成してください。また、ファイル名は 「(7桁の学籍番号)_第x回_画像処理レポート.docx」 (xの部分は何回目の課題なのかを記入)に変更してください。
課題作成上の注意
課題を作成する際には、プログラムは別に .py ファイルで作成して、本レポートと一緒に圧縮したうえで提出してください。また、Jupyter Notebook形式のファイル (拡張子が.ipynb)のものは受け付けません。
加えて、プログラムを添付したのみで内容に関する説明や結果に関する考察のないもの、単なる結果の羅列になっているもの(またはそのように見えるもの)は採点しませんのでご注意ください。
テンプレート・マッチングによる数字の検出
OpenCVの cv2.matchTemplate を用いて、次の数独の画像に対して1から9までの数字を検出し、異なる色の矩形で囲んで表示しなさい。この際、 cv2.matchTemplate で使用するマッチング手法を
cv2.TM_SQDIFF: SSDを用いる方法cv2.TM_CCORR_NORMED: 正規化相互相関 (NCC) を用いる方法cv2.TM_CCOEFF_NORMED: 正規化相関係数 (ZNCC) を用いる方法
の3種類について試し、結果を比較しなさい。